Compression for AGI - Jack Rae | Stanford MLSys #76
Summary
TLDRIn episode 76 of the Stanford MLS seminar series, the focus is on the intriguing intersection of compression and AGI (Artificial General Intelligence), featuring guest speaker Jack Ray from OpenAI. The talk delves into foundational models and their significant role in shaping the future of machine learning, emphasizing the importance of understanding their training objectives, limitations, and potential. Jack Ray presents a detailed exploration of compression as a key to unlocking AGI, discussing generative models as lossless compressors and highlighting the concept of minimum description length. Through this insightful discussion, the seminar sheds light on the intricate dynamics of foundation models, urging the audience to think deeply about their applications and the broader implications for AI research.
Takeaways
- 😃 Large language models like GPT-3 are state-of-the-art lossless compressors, able to compress data at rates better than traditional algorithms like gzip.
- 🤔 The minimum description length principle, which aims to find the smallest possible representation of data, has deep philosophical roots and may be key to achieving artificial general intelligence (AGI).
- 🧐 Training large language models is essentially a process of lossless compression, where the objective is to minimize the number of bits required to encode the training data.
- 💡 Scaling up model size and training data can lead to better compression and potentially improved generalization, but algorithmic advances beyond just scaling are also important.
- ⚠️ While compression is a rigorous objective, evaluating models solely on compression metrics may be uninformative, and tracking emergent capabilities is crucial.
- 🔍 Arithmetic encoding provides a way to losslessly compress data using a language model's predictions, though the process is computationally expensive.
- ✨ Architectures that can adaptively allocate compute based on input complexity, like the S4 model, may be important for efficiently compressing multi-modal data like images and audio.
- 🚧 Lossy compression, while related, is distinct from the lossless compression objective and may not lead to better generalization.
- 🔑 The description length of a model itself (e.g., the code to instantiate it) is typically small compared to the compressed data size, regardless of model scale.
- 🌱 Future breakthroughs in areas like data efficiency, adaptive compute, and new architectures could lead to further paradigm shifts in compression and generalization capabilities.
Q & A
What is the main topic of the talk?
-The main topic of the talk is compression for artificial general intelligence (AGI), and how techniques like lossless compression using large language models can potentially help in solving perception and generalization problems.
Why is the minimum description length principle important according to the speaker?
-The speaker argues that seeking the minimum description length of data may be an important principle in solving perception and generalizing well, as it has a rigorous mathematical foundation dating back to philosophers like Aristotle and William of Ockham.
How are large language models related to lossless compression?
-The speaker explains that large language models are actually state-of-the-art lossless compressors, as training them involves minimizing the negative log-likelihood over the training data, which is equivalent to lossless compression.
Can you explain the example of Satya and Sundar used to illustrate lossless compression?
-The example involves Satya encoding a dataset using a trained language model and arithmetic coding, and sending the encoded transcripts and model code to Sundar. Sundar can then reconstruct the original dataset by running the code and using arithmetic decoding with the predicted token probabilities.
What is the potential recipe for solving perception and moving towards AGI according to the speaker?
-The recipe is to first collect all useful perceptual information, and then learn to compress it as best as possible with a powerful foundation model, through techniques like scaling data and compute, or algorithmic advances.
What is the main limitation of the compression approach mentioned by the speaker?
-One limitation is that modeling and compressing everything at a low level (e.g., pixels for images) may be computationally expensive and inefficient, so some form of filtering or semantic understanding may be needed first.
How does the speaker view the role of reinforcement learning in relation to compression?
-The speaker notes that while compression is important for observable data, reinforcement learning and on-policy behavior are still crucial for gathering useful information that may not be directly observable.
What is the speaker's opinion on the Hutter Prize for lossless compression?
-The speaker believes that while the Hutter Prize aims to promote compression, it has not been fruitful because it focuses on compressing a small, fixed amount of data, underestimating the benefits of scaling data and compute.
How does the compression perspective inform the development of new architectures?
-The speaker suggests that the compression perspective could inspire research into architectures that can adapt their compute and attention based on the information content of the input, similar to how biological systems allocate resources non-uniformly.
What is the speaker's overall view on the importance of compression research?
-The speaker believes that while the compression objective provides a rigorous foundation for generalization, the primary focus should be on evaluating and tracking the emergence of new capabilities in models, as those are ultimately what people care about.
Outlines
🎉 Introduction to Compression and AGI Seminar
The Stanford MLS seminar series introduces a talk by Jack Ray from OpenAI, focusing on compression for Artificial General Intelligence (AGI). The seminar highlights the partnership with CS324 on advances in Foundation Models. Participants are encouraged to engage and ask questions via YouTube chat or Discord. The session promises insightful discussions on the training objectives of foundation models, their limitations, and the significance of compression in the context of AGI.
📊 Foundation Models and Minimum Description Length
This section delves into the concept of minimum description length (MDL) and its relevance to understanding and improving foundation models. Jack Ray discusses the historical and philosophical underpinnings of seeking the minimum description length for data compression and generalization, referencing Solonoff's theory of inductive inference. The segment also explores generative models as lossless compressors, highlighting how large language models, despite their size, excel in state-of-the-art lossless data compression.
🔍 Exploring Lossless Compression with Large Language Models
Jack Ray elucidates the mechanics of lossless compression in large language models through a detailed example involving LLaMA models. He demonstrates that larger models, such as the 65 billion parameter version, achieve better compression, hence suggesting superior generalization capabilities. The talk emphasizes the counterintuitive nature of large language models being efficient lossless compressors and explains the mathematical basis for evaluating the compression efficiency of these models.
🌐 Arithmetic Encoding and Model Training
The seminar continues with an in-depth discussion on arithmetic encoding as a method for data compression. Through a hypothetical scenario involving two individuals, Satya and Sundar, Ray illustrates how arithmetic encoding and decoding work in tandem with a generative model to achieve lossless compression of a dataset. This process underlines the non-dependence of compression efficiency on the size of the neural network but rather on the model's ability to predict next tokens accurately.
📈 Towards AGI: The Importance of Compression
Jack Ray outlines a two-step approach towards achieving AGI: collecting useful perceptual information and compressing it efficiently using powerful foundation models. He argues that any research method improving compression can advance capabilities towards better perception, supporting the idea with examples of how lossless compression aids in understanding and generalization. Ray also addresses common confusions regarding lossy vs. lossless compression and their implications for neural networks.
🚀 The Future of Compression in AI Research
In the final part of the seminar, Ray explores potential limitations and future directions for compression in AI research. He touches on practical challenges, such as the computational expense of pixel-level image modeling, and the need for novel architectures that adapt to the informational content of inputs. The discussion concludes with reflections on the integral role of compression in driving advancements in AI and the continuous pursuit of algorithmic improvements alongside computational scaling.
Mindmap
Keywords
💡Compression
💡Minimum Description Length
💡Generative Models
💡Arithmetic Coding
💡Scaling
💡Foundation Models
💡AGI (Artificial General Intelligence)
💡Perception
💡Lossless Compression
💡Retrieval
Highlights
Compression is a has been a objective that actually we are generally striving towards as we build better and larger models which may be counter-intuitive, given the models themselves can be very large.
Generative models are actually lossless compressors and specifically large language models are actually state of the art lossless compressors which may be a counter-intuitive point to many people.
Race Islanders' theory of inductive inference states that if you have a universe of data generated by an algorithm and observations of that universe encoded as a data set, they are best predicted by the smallest executable Archive of that data set, known as the minimum description length.
The size of the lossless compression of a data set can be characterized as the negative log likelihood from a generative model evaluated over the data set, plus the description length of the generative model.
Generative models like large language models are state-of-the-art lossless compressors, able to compress datasets like the one used to train the 65B parameter LLaMA model by 14x compared to the original data size.
Arithmetic encoding allows mapping a token to a compressed transcript using exactly -log2(p) bits, where p is the model's predicted probability for that token. Arithmetic decoding can recover the original token from the transcript if the probability distribution is known.
Larger models trained for more compute steps tend to achieve better compression, explaining their superior generalization performance despite increased model size.
Retrieval-augmented language models that can look ahead at future tokens would be "cheating" from a compression standpoint and may fool performance metrics without true generalization gains.
Model architectures that can dynamically allocate compute based on information content, similar to how human perception works, could improve the inefficiency of current models that spend uniform compute on all inputs.
Pixel-level image and video modeling is very compute-intensive with current architectures but may be viable with architectures that can gracefully process inputs at the appropriate "thinking frequency".
The Hutter prize's small 100MB data limit failed to incentivize meaningful compression research, while the transition to large language models provided a bigger boost.
While compression is a rigorous objective, model capabilities that people fundamentally care about should be continually evaluated alongside compression metrics.
Training for multiple epochs may be justified from a compression perspective if treated as a form of replay, where only predictions on held-out data are scored.
S4 and other architectures that enable longer context lengths and adaptive computation could help model different modalities like audio and images more efficiently.
The pace of innovation in foundation models and their applications is incredibly rapid, with amazing developments expected weekly or bi-weekly in 2023.
Transcripts
hello everyone and welcome to episode 76
of the Stanford MLS seminar series
um today of course we're or this year
we're very excited to be partnered with
cs324 advances in Foundation models
um today I'm joined by Michael say hi
and ivonica
um and today our guest is Jack Ray from
openai and he's got a very exciting talk
uh prep for us about compression and AGI
um so so we're very excited to listen to
him as always if if you have questions
you can post them in YouTube chat or if
you're in the class there's that Discord
Channel
um so so to keep the questions coming
and after his talk we will we'll have a
great discussion
um so with that Jack take it away
okay fantastic thanks a lot
and right
okay so
um today I'm going to talk about
compression for AGI and the theme of
this talk is that I want people to kind
of think deeply about uh Foundation
models and their training objective and
think deeply about kind of what are we
doing why does it make sense what are
the limitations
um
this is quite a important topic at
present I think there's a huge amount of
interest in this area in Foundation
models large language models their
applications and a lot of it is driven
very reasonably just from this principle
that it works and it works so it's
interesting but if we just kind of sit
within the kind of it works realm it's
hard to necessarily predict or have a
good intuition of why it might work or
where it might go
so some takeaways that I want so I hope
people like people hopefully to take
from this tour car some of them are
quite pragmatic so I'm going to talk
about some background on the minimum
description length and why it's seeking
the minimum description length of our
data may be an important role in solving
perception uh I want to make a
particular point that generative models
are actually lossless compressors and
specifically large language models are
actually state of the art lossless
compressors which may be a
counter-intuitive point to many people
given that they are very large and use a
lot of space and I'm going to unpack
that
in detail and then I'm also going to
kind of end on some notes of limitations
of the approach of compression
so
let's start with this background minimum
description length and why it relates to
perception so
even going right back to the kind of
ultimate goal of learning from data we
may have some set of observations that
we've collected some set of data that we
want to learn about which we consider
this small red circle
and we actually have a kind of a
two-pronged goal we want to learn like
uh how to kind of predict and understand
our observed data with the goal of
understanding and generalizing to a much
larger set of Universe of possible
observations so we can think of this as
if we wanted to learn from dialogue data
for example we may have a collection of
dialogue transcripts but we don't
actually care about only learning about
those particular dialogue transcripts we
want to then be able to generalize to
the superset of all possible valid
conversations that a model may come
across right so
what is an approach what is a very like
rigorous approach to trying to learn to
generalize well I mean this has been a
philosophical question for multiple
thousands of years
um
and even actually kind of full Century
BC uh there's like some pretty good
um principles that philosophers are
thinking about so Aristotle had this
notion of
um
assuming the super superiority of the
demonstration which derives from fewer
postulates or hypotheses so this notion
of uh we have some
[Music]
um
um simple set of hypotheses
um
then this is probably going to be a
superior description of a demonstration
now this kind of General kind of simpler
is better
um
theme is more recently attributed to
William 14th century or Cam's Razer this
is something many people may have
encountered during a machine learning or
computer science class
he is essentially continuing on this
kind of philosophical theme the simplest
of several competing explanations is
always likely likely to be the correct
one
um now I think we can go even further
than this within machine learning I
think right now Occam's razor is almost
used to defend almost every possible
angle of research but I think one
actually very rigorous incarnation of
what comes Razer is from race Island's
theory of inductive inference 1964. so
we're almost at the present day and he
says something quite concrete and
actually mathematically proven which is
that if you have a universe of data
which is generated by an algorithm and
observations of that universe so this is
the small red circle
encoded as a data set are best predicted
by the smallest executable Archive of
that data set so that says the smallest
lossless prediction or otherwise known
as the minimum description length so I
feel like that final one is actually
putting into mathematical and quite
concrete terms
um these kind of Notions that existed
through timing velocity
and it kind of we could even relate this
to a pretty I feel like that is a quite
a concrete and actionable retort to this
kind of
um quite
um murky original philosophical question
but if we even apply this to a
well-known philosophical problem cells
Chinese room 4 experiment where there's
this notion of a computer program or
even a person kind of with it within a
room that is going to perform
translation from English English to
Chinese and they're going to
specifically use a complete rulebook of
all possible
inputs or possible say English phrases
they receive and then and then the
corresponding say Chinese translation
and the original question is does this
person kind of understand how to perform
translation uh and I think actually this
compression argument this race on this
compression argument is going to give us
something quite concrete here so uh this
is kind of going back to the small red
circle large white circle if if we have
all possible translations and then we're
just following the rule book this is
kind of the least possible understanding
we can have of translation if we have
such a giant book of all possible
translations and it's quite intuitive if
we all we have to do is coin a new word
or have a new phrase or anything which
just doesn't actually fit in the
original book this system will
completely fail to translate because it
has the least possible understanding of
translation and it has the least
understandable version of translation
because that's the largest possible
representation of the the task the data
set however if we could make this
smaller maybe we kind of distill
sorry we distill this to a smaller set
of rules some grammar some basic
vocabulary and then we can execute this
program maybe such a system has a better
understanding of translation so we can
kind of grade it based on how compressed
this rulebook is and actually if we
could kind of compress it down to the
kind of minimum description like the
most compressed format the task we may
even argue such a system has the best
possible understanding of translation
um now for foundation models we
typically are in the realm where we're
talking about generator model one that
places probability on natural data and
what is quite nice is we can actually
characterize the lossless compression of
a data set using a generator model in a
very precise mathematical format so race
on enough says we should try and find
the minimum description length well we
can actually try and do this practically
with a generator model so the size the
lossless compression of our data set D
can be characterized as the negative log
likelihood from a genetic model
evaluated over D plus the description
length of this generator model so for a
neural network we can think of this as
the amount of code to initialize the
neural network
that might actually be quite small
this is not actually something that
would be influenced by the size of the
neural network this would just be the
code to actually instantiate it so it
might be a couple hundred kilobytes to
actually Implement a code base which
trains a transformer for example and
actually this is quite a surprising fact
so what does this equation tell us does
it tell us anything new well I think it
tells us something quite profound the
first thing is we want to minimize this
general property and we can do it by two
ways one is via having a generative
model which has better and better
performance of our data set that is a
lower and lower negative log likelihood
but also we are going to account for the
prior information that we inject into F
which is that we can't stuff F full of
priors such that maybe it gets better
performance but overall it does not get
a bit of a compression
um so
on that note yeah compression is a a
cool way of thinking about
how we should best model our data and
it's actually kind of a non-gameable
objective so contamination is a big
problem within uh machine learning and
trying to evaluate progress is often
hampered by Notions of whether or not
test sets are leaked into training sense
well with compression this is actually
not not something we can game so imagine
we pre-trained F on a whole data set D
such that it perfectly memorizes the
data set
AKA such that the probability of D is
one log probability is zero in such a
case if we go back to this formula the
first term will zip to zero
however now essentially by doing that by
injecting and pre-training our model on
this whole data set we have to add that
to the description length of our
generative model so now F not only
contains the code to train it Etc but it
also contains essentially a description
length of d
so in this setting essentially a
pre-contaminating f it does not help us
optimize the compression
and this contrasts to regular test set
benchmarking where we may be just
measuring test set performance and
hoping that measures generalization and
is essentially a proxy for compression
and it can be but also we can find lots
and lots of scenarios where we
essentially have variations of the test
set that have slipped through the net in
our training set and actually even right
now within Labs comparing large language
models this notion of contamination
affecting eval resources a continual
kind of phone in um in in the side of
kind of clarity
Okay so we've talked about philosophical
backing of the minimum description
length and maybe why it's a sensible
objective
and now I'm going to talk about it
concretely for large language models and
we can kind of map this to any uh
generative model but I'm just going to
kind of ground it specifically in the
marsh language model so if we think
about what is the log problem of our
data D well it's the sum of our next
token prediction of tokens over our data
set
[Music]
um
so this is something that's essentially
our training objective if we think of
our data set D
um and we have one Epoch then this is
the sum of all of our training loss so
it's pretty tangible term it's a real
thing we can measure and F is the
description length of our
Transformer language model uh and
actually there are people that have
implemented a Transformer and a training
regime just without any external
libraries in about I think 100 to 200
kilobytes so this is actually something
that's very small
um and and as I said I just want to
enunciate this this is something where
it's not dependent on the size of our
neural network so if a piece of code can
instantiate a 10 layer Transformer the
same piece of code you can just change a
few numbers in the code it can
instantiate a 1000 layer Transformer
actually the description length of our
initial Transformer is unaffected really
by how large the actual neural network
is we're going to go through an example
of actually using a language model to
losslessly compress where we're going to
see why this is the case
okay so let's just give like a specific
example and try and ground this out
further so okay llama it was a very cool
paper that came out from fair just like
late last week I was looking at the
paper here's some training curves
um now forgetting the smaller two models
there are the two largest models are
trained on one Epoch of their data set
so actually we could sum their training
losses uh AKA this quantity
and we can also roughly approximate the
size of of the um of the code base that
was used to train them
um and therefore we can see like okay
which of these two moles the 33b or the
65b is the better compressor and
therefore which would we expect to be
the better model at generalizing and
having greater set of capabilities so
it's pretty it's going to be pretty
obvious at 65b I'll tell you why firstly
just to drum this point home these
models all have the same description
length they have different number of
parameters but the code that's used to
generate them is actually of same of the
same complexity however they don't have
the same integral of the training loss
65b has a smaller integral Windows
training loss
and therefore if we plug if we sum these
two terms we would find that 65b
essentially creates the more concise
description of its training data set
okay so that might seem a little bit
weird I'm going to even plug some actual
numbers in let's say we assume it's
about one megabyte for the code to
instantiate and train the Transformer
and then if we actually just calculate
this roughly it looks to be about say
400 gigabytes
um
you have some of your log loss
converting into bits and then bytes it's
going to be something like 400 gigabytes
and this is from an original data set
which is about 5.6 terabytes of rortex
so 1.4 trillion tokens times four is
about 5.6 terabytes so that's a
compression rate of 14x
um the best text compressor on the
Hudson prize is 8.7 X so the takeaway of
this point is
um actually as we're scaling up and
we're creating more powerful models and
we're training them on more data we're
actually creating something which
actually is providing a lower and lower
lossless compression of our data even
though the intermediate model itself may
be very large
okay so now I've talked a bit about how
large language models are state of the
art lossless compressors but I just want
to maybe go through the mechanics of how
do we actually get a something like a
generative model literally losslessly
compress this may be something that's
quite mysterious like what is happening
like
when you actually losslessly compress
this thing is it the weights or is it
something else
so I'm going to give us a hypothetical
kind of scenario we have two people sat
here in Sundar Satya wants to send a
data set of the world's knowledge
encoded in D to send R they both have
access to very powerful supercomputers
but there's a low bandwidth connection
we are going to use a trick called
arithmetic encoding as a way of
communicating the data set so say we
have a token x a timestep t from of some
vocab and a probability distribution p
over tokens
arithmetic encoding without going into
the nuts and bolts is a way of allowing
us to map our token x given our
probability distribution over tokens to
some Z
where Z is essentially our compressed
transcripts of data and Z is going to
use exactly minus log 2 p t x t bits so
the point of this step is like
arithmetic encoding actually Maps it to
some kind of like floating Point number
as it turns out and it's a real
algorithm this is like something that
exists in the real world it does require
technically infinite Precision to to use
exactly these number of bits and
otherwise you maybe you're going to pay
a small cost for implementation but it's
roughly approximately optimal in terms
of the encoding and we can use
arithmetic decoding
um to take this encrypted transcript and
as long as we have our probability
distribution of tokens we can then
recover the original token so we can
think about probability probability
distribution as kind of like a key it
can allow us to kind of lock in a
compressed copy of our token and then
unlock it
so if p is uniform so there's no
information about our tokens then this
would be this one over v p is just one
over the size of V so we can use log 2 V
bits of space uh that is just
essentially the same as naively storing
in binary uh our our XT token if p is an
oracle so it knows like exactly what the
token was going to be
so P of x equals one then log 2p equals
zero and this uses zero space so these
are the two extremes and obviously what
we want is a generative model which
better and better molds our data and
therefore it uses less space
so what would actually happen in
practice if Satya can take his data set
of tokens trainer Transformer and get a
subsequent set of probabilities uh over
the tokens like so next token prediction
and then use arithmetic encoding to map
it to this list of transcripts and this
is going to be of size sum of negative
log likelihood of your Transformer over
the data set
and he's also going to send he's going
to send that list of transcripts and
some code that can deterministically
train a larger Transformer
and so
he sends those two things what does that
equal in practice the size of f the size
of your generator model description plus
the size of your some of your negative
log likelihood of your data set so as
you can see it doesn't matter whether
the Transformer was one billion
parameters one trillion parameters
plus plus he's not actually sending the
neural network he's sending the
transcript of encoded logits plus the
code
and then on the other side Sundar can
run this code which is deterministic and
the mod is going to run the neural
network it gives a probability
distribution to the first token he's
going to use arithmetic decoding with
that to get his first token you can
either train on that or whatever the
code does so then continue on
predict the next token etc etc and
essentially
iteratively go through and recover the
whole data set
um so this is kind of like almost a
fourth experiment because in practice to
send this data at 14x compressed
compression say if we're talking about
the Llama model uh that's it's a bit
more compressed than gzip but this is
requiring a huge amount of intermediate
compute switches to train a large
language model which feels inhibitive
but this thought experiment is really
derived not because we actually might
want to send data on a smaller and
smaller bandwidth it's also just derived
to kind of explain and prove why we can
actually losslessly compress with
language models and why that is their
actual objective
um and if this kind of setup feels a
little bit contrived well the fun fact
is this is the exact setup that called
Shannon was thinking about
um when he kind of proposed language
models in the 40s he was thinking about
having a discrete set of data and how
can we better communicate to overload
over a low bandwidth Channel and
language models and entropy coding
essentially was the topic that he was
thinking about about labs
Okay so we've talked mechanically about
well we've talked about the philosophy
of kind of why do why why be interested
in description length relating it to
generalization talks about why
generative models are lossless
compressors talked about why our current
large language models are actually
state-of-the-art lossless compressors
than our providing some of the most
compressed representations of our source
data so let's just think about solving
perception and moving towards AGI what's
the recipe well it's kind of a two-step
process one is collect all useful
perceptual information that we want to
understand and the second is learn to
compress it as best as possible with a
powerful Foundation model
so the nice thing about this is it's not
constrained to a particular angle for
example you can use any research method
that improves compression and I would
posit that this will further Advance our
capabilities towards perception based on
this rigorous foundation so that might
be a better architecture it may be scale
further scaling of data and computes
this is in fact something that's almost
become a meme people say scale is all
you need but truly I think scale is only
going to benefit as long as it is
continuing to significantly improve
compression but you could any use any
other technique and this doesn't have to
be just a regular generative model it
could even we could even maybe spend a
few more bits on the description length
of F and add in some tools add in things
like a calculator allow it to make use
of tools to better predict its data
allow it to retrieve over the past use
its own synthetic data to generate and
then learn better there's many many
angles we could think about that are
within the scope of a model
better better compressing it Source data
to generalize over the universe of
possible observations
I just want to remark at this point on a
very common point of confusion on this
topic which is about lossy compression
so I think it's a very reasonable
um
thought to maybe confuse what a neural
network is doing with glossy compression
especially because
information naturally seeps in from the
source training data into the weights of
a neural network and neural network can
often memorize it often does memorize
and can repeat many things that it's
seen but it doesn't repeat everything
perfectly so it's lossy and it's also
kind of a terrible lossy compression
algorithm so if in the velocity
compression case you would actually be
transmitting the weights of the
parameters of a neural network and they
can often actually be larger than your
Source data so I think there's a very
interesting New Yorker article about
about this kind of Topic in general kind
of thinking about you know what are what
are language models doing what are
Foundation models doing and I think
there's a lot of confusion in this
article specifically on this topic where
from the perspective of glossy
compression
and neural network feels very kind of
sub-optimal it's losing information in
Red so it doesn't even do reconstruction
very well and it's potentially bloated
and larger and has all these other
properties
I just wanted to take this kind of
point to reflect
on the original goal which is we really
care about understanding and
generalizing to the space of the
universe of possible observations so we
don't care and we don't train towards
reconstructing our original data
um I think if we did then this article
basically concludes like if we did just
care about reconstructing this original
data like why do we even train over it
why not just keep the original data as
it is and I think that's a very valid
point uh but if we care instead about
loss like a lossless compression of this
then essentially this talk is about
linking that to this wider problem of
generalizing to many many different
types of unseen data
great so I've talked about
the mechanics of compression with
language models and linking it to this
confusion of velocity compression what
are some limitations that I think are
pretty valid
um so I think
there's one concern with this approach
which is that it may be just the right
thing to do or like an unbiased kind of
attempt at solving perception but maybe
it's just not very pragmatic and
actually trying to kind of model
everything and compress everything it
may be kind of correct but very
inefficient so I think Image level
modeling is a good example of this where
modeling a whole image at the pixel
level has often kind of been
prohibitively expensive to like work
incredibly well and therefore people
have changed the objective or or ended
up modeling a slightly
more semantic level
um and I think even if it maybe seems
plausible now we can go back to pixel
level image modeling and maybe we just
need to tweak the architecture if we
turn this to video modeling every pixel
of every frame it really feels
preemptively crazy and expensive so one
limitation is you know maybe we do need
to kind of first filter like what are
what are all the pieces of information
that we know we definitely are still
keeping and we want to model but then
try and have some way like filtering out
the extraneous communicate computation
the the kind of bits of information we
just don't need and then maybe we can
then filter out to a much smaller subset
and then and then we losslessly compress
that
um
another very valid point is I think this
is often framed uh to people that maybe
are thinking that this is like the only
ingredient for AGI is that crucially
there's lots of just very useful
information in the world that is not
observable and therefore we can't just
expect to compress all observable
observations achieve AGI because
there'll just be lots of things we're
missing out
um so I think a good example of this
would be something like Alpha zero so
playing the game of Go
um
I think if you just observe the limited
number of human games that have ever
existed one thing that you're missing is
all of the intermediate search trees of
all of these expert players and one nice
thing about something like Alpha zero
with its kind of self-play mechanism is
you essentially get to collect lots of
data of intermediate search trees of
many many different types of games
um so that kind of on policy behavior of
like actually having an agent that can
act and then Source out the kind of data
that it needs I think is still very
important so and in no way kind of
diminishing uh the importance of RL or
on policy kind of behavior
um but I think yeah for for everything
that we can observe
um that this is kind of like the
compression story ideally applies
great so going to conclusions
um
so compression is a has been a objective
that actually we are generally striving
towards as we build better and larger
models which may be counter-intuitive
given the models themselves can be very
large
um
the most known entity right now the one
on a lot of people's minds to better
compression is actually scale scaling
compute
um and and maybe even scaling memory but
scale isn't all you need there are many
algorithmic advances out there that I
think very interesting research problems
and
and if we look back uh basically all of
the major language modeling advances
have been synonymous with far greater
text compression so even going back from
uh the creation of engram models on pen
and paper and then kind of bringing them
into computers and then having like kind
of computerized huge tables of engram
statistics of language this kind of
opened up the ability for us to do
um things like speech to text with a
reasonable accuracy
um bringing that system to uh deep
learning via rnns has allowed us to have
much more fluent text that can span
paragraphs and then actually be
applicable to tasks like translation and
then in the recent era of large-scale
Transformers we're able to further
extend the context and extend the model
capabilities via compute such that we
are now in this place where we're able
to use
language models and Foundation models in
general
um to understand very very long spans of
text and to be able to create incredibly
useful or incredibly tailored incredibly
interesting
um Generations so I think this is going
to extend but it's a big and interesting
open problem uh what are going to be the
advances to kind of give us further
Paradigm shifts in this kind of
compression uh improved compression
right so
um yeah this talk is generally just a
rehash for the message of
former and current colleagues of mine
especially Marcus to Alex Graves Joel
Vanessa so I just want to acknowledge
them and uh thanks a lot for listening
I'm looking forward to uh chatting about
some questions
great thanks so much Jack
um I'm actually going to ask you to keep
your slides on the screen because I
think we had some uh questions about uh
just kind of uh understanding the
um some some of the mathematical
statements in the talk so I think it
would be helpful to to kind of go go
back over some of the slides yeah I
think uh some people were confused a bit
by the arithmetic decoding
um so in particular uh maybe it'll be
useful to to go back to discussion of
the arithmetic decoding and uh I think
people are a bit confused about
um how is it possible for the receiver
to decode the message and get the
original data set back without having
access to the train bottle
yeah
um well okay
um I'll do in two steps so one let's
just imagine they don't have the fully
trained model that they have a partially
trained model
and so they are able to get a next token
prediction
and then
um
they have the the receiver also has some
of the encoded transcripts at T this
allows them I guess maybe here in the
case of language modeling this would
look like XT plus one say if it was like
PT Plus one but anyway
um this may allow them to recover the
next token and then they're going to
build it up in this way so maybe I'll
just delay on this particular Slide the
idea it would look like is we we the
receiver does not receive the neural
network it just receives the code to
instantiate kind of the fresh neural
network and run the identical training
setup that it saw before and obviously
the training setup as it saw before
we're going to imagine like batch size
of one one token at a time just for
Simplicity so uh and let's just imagine
maybe there's like a beginning of text
token here first so
so the receiver so now he just has to
run the code at first there's nothing to
decode yet there's no tokens and there's
a fresh neural network uh that's going
to give us like a probability
distribution for the first token and so
he's got this probability distribution
for the first token and he's got the
transcript
um of what that token should be and you
can use arithmetic decoding to actually
recover that first token
and then let's imagine for Simplicity we
actually like train like one SGD step on
one token at a time so we take our SGD
step and then we have the model that's
like was used to predict the next token
so we can get that P2 we have Z2 and
then we can recover X2 so now we've
recovered two tokens and we can
essentially do this iteratively
essentially reproduce this whole
training procedure on the receiving side
and dur as we reproduce the whole
training procedure we actually recover
the whole data set
yeah so it's a crazy expensive way of
actually encrypt like uh compressing
data and it might feel once again like
oh but since we're not going to
literally do that it's too expensive why
do I need to learn about it and this
really is just a way of it's like a
proof by Construction in case
um you were like you know is this
actually true like is the lossless
compressed D actually equal to this and
it's like yeah like here's how we
literally can do it and it's just the
reason we don't do it in practice is
because it would be very expensive but
there's nothing actually stopping us
it's not like completely theoretical
idea yeah
okay so all right so to kind of maybe
I'll try to explain it back to you and
then um if people on the chat and the uh
Discord shell of questions
um they they can ask and then we can we
can get some clarifications so basically
you're saying you initialize a model
um you have it do like some beginning of
token thing and it'll predict what what
it thinks the first uh what the first
token should be
um and then you use arithmetic encoding
to somehow say okay here's the here's
the prediction and then we're going to
correct it to the the actual what the
actual token is so that Z1 has enough
information to figure out what that
actual first token is yeah and then you
use that first token run one step of SGD
predict you know get the probability
distribution for the second one now you
have enough information to decode uh the
the second thing like maybe
you know uh yeah uh it's like take the
ARG Max but you know take the the third
rmx or Max or something like that
um and then so you're saying that that
is enough information to reconstruct the
the data set D exactly yeah
okay great great so uh yeah so I I
personally you know I understand a bit
better now and that that also makes
sense why the model
um you know the the model weights and
the the size of the model are not uh
actually part of that that compression
um one question that that I also had
while
um you know uh talking through that
explanation so how does that you know
compression now go back and uh how's
that related to the loss curve that you
get
um at the end of training is it that the
better your model is by the end of
training then you need to communicate
less information just like I don't know
take art Max or something like that so I
just want to say yeah like this is a
Formula if we look at this this is
basically pretty much the size of your
arithmetic encoded transcript
and this is you like your the log
negative log likelihood of your next
token prediction at every step so let's
just imagine this was batch size one
this is literally the sum
of every single training loss point
because it and the summing under a curve
this is like the integral into the Curve
so this
this value equals this and I did I did
it just by summing under this curve so
it's like a completely real quantity you
get you actually even are getting from
your training curve
so it's a little bit different to just
the final training loss it's the
integral during the whole training
procedure
great so okay and then yeah
we can think of during training we're
going along and let's imagine we're in
the one Epoch scenario we're going along
and then every single step we're
essentially get a new kind of out of uh
out of sample like a new
sequence to try and predict and then all
we care about is trying to predict that
as best as possible and then continuing
that process and actually what we care
about is essentially all predictions
equally and trying to get the whole
thing to learn like either faster
initially and then to a lower value or
however we want we just want to minimize
this integral and basically what this
formula says it can minimize this
integral we should get something that's
essentially better and better
understands uh the data or at least
generalizes better and better
gotcha okay cool
um all right so uh let me see I think
now is a good time to end the screen
share
great okay cool
um and now uh we can go to to some more
questions uh in the in the class so
there there were a couple questions
around
um kind of uh what does this compression
uh Viewpoint allow you to do so there's
a couple questions on so has this mdl
perspective kind of
um informed the ways that you would that
we train models now or any of the
architectures that we've done now yeah
can I I think the most like immediate
one is that it clarifies a long-standing
point of confusion even within the
academic Community which is
um people don't really understand why a
larger model that seems to even
um
like why should it not be the case
that's smaller neural network less
parameters generalizes better I think
people have taken
um
like principles from like when they
study linear models and they were
regularized to have like less parameters
and there was some bounds like VC bounds
on
um
generalization and there was this
General notion of like less parameters
is what outcomes razor refers to
um one perspective this helps is a like
I think it frees up our mind of like
what is the actual objective that we
should expect to optimize towards that
will actually get us the thing we want
which is better generalization so for me
that's the most important one even on
Twitter I see it like professors in
machine learning occasionally you'll see
like they'll say some like smaller
models are more intelligent than larger
models kind of it's kind of almost like
a weird
um
um Motif that is not very rigorous so I
think one thing that's useful about this
argument is there's a pretty like
like strong like mathematical link all
the way down it goes like it starts at
solynoff's theory of induction which is
proven and then we have like a actual
mathematical link to an objective and
then
yeah it kind of like to lossless
compression and then it all kind of
links up so
um yeah I think another example would
even be like this this very I think it's
a great article but like the Ted Chang
article on uh lossless compression which
people haven't read I still recommend
reading I think
once you're not quite in a world where
like you have like a well-justified uh
motivation for doing something then
there's like lots of kind of confusion
about whether or not this whole approach
is even reasonable
um yeah so I think for me a lot of it's
about guidance but then on a more
practical level
um there are things that you can do that
would essentially kind of break uh you
would stop doing compression and you
might not notice it and then I think
this also guides you to like not do that
and I'll give you one example which is
something I've worked on personally
which is retrieval so for retrieval
augmented language models you can maybe
retrieve your whole training set and
then use that to try and improve your
predictions as you're going through now
if we think about compression one thing
that you can't do one thing that would
essentially cheating would be allow
yourself to retrieve over like future
tokens that you have not seen yet
um if you do that it's obvious like um
it might not be obvious immediately
because it was a tricky setup but in my
kind of like Satya Sundar encoding
decoding setup if you had some system
which can look to the Future that just
like won't work with that encoding
decoding setup and it also essentially
is cheating and
um
yeah so I think
essentially it's something which would
it could help your like test set
performance it might even make your
training loss look smaller but it
actually didn't improve your compression
and potentially you could fool yourself
into
um into like expecting a much larger
performance Improvement than you end up
getting in practice so I think sometimes
like you can help yourself
try and like set yourself up for
something that should actually
generalize better and do better on
Downstream evals than
um by kind of like thinking about this
kind of training objective
I see it also probably informs the type
of architectures you want to try because
if you're uh I think that that comments
about like the size of the code being
important is was really interesting
because if you need you know 17
different layers and every other uh and
every other a different module in every
layer or something that that kind of
increases the amount of information that
you need to communicate over
um yeah yeah
um it can be I could imagine on that
note like right now our setup is
essentially the prior information we put
into neural networks it's actually kind
of minuscule really and obviously
um with biological beings we have like
DNA we have like prior as like kind of
stored information which is is at least
larger than really what um the kind of
prize that we put into um
and neural networks I mean one thing
when I was first going through this I
was thinking maybe there should be more
kind of learned information that we
transfer between neural networks more of
a kind of like DNA
um and maybe like I mean we initialize
neural networks right now essentially
like gaussian noise with some a few
properties but like maybe if there was
some kind of like learned initialization
that we distill over many many different
types of ways of training neural
networks that wouldn't add to our size
of f too much but it might like mean
learning is just much faster so yeah
hopefully also the perspective might
like kind of spring out kind of
different and unique and creative like
themes of research
okay
um there there's another interesting
question from the class about the uses
of this kind of compression angle
um and the question is uh could could
the compression be good in some way by
allowing us to gain like what sorts of
higher level understanding or Focus
um on the important signal in the data
might we be able to get from the
um uh from from the lossy compression so
if we could like for example better
control the information being lost would
that allow us to gain any sort of higher
level understanding
um about kind of what what's important
in the data
um
so I think
that there is like a theme of research
trying to
um use essentially just like
the compressibility of data as at least
as a proxy for like quality
so that's one like very concrete theme
uh like
I mean this is pretty standard
pre-processing trick but
if your like data is just uncompressible
with a very simple text Express like
Giza as a data preprocessing tool then
maybe it's just like kind of random
noise and maybe you don't want to spend
any compute training or a large
Foundation model over it similarly I
think there's been
pieces of work there's a paper from 2010
that was like intelligent selection of
language model pre-training data or
something by Lewis and Moore and in that
one they look at
um they're trying to like select
training data that will be maximally
useful
um
for some Downstream tasks and
essentially what they do is they look at
like what data is best compressed
um when going from just like a regular
pre-trained language model to one that's
been specialized on that Downstream task
and they use that as a metric for data
selection they found that's like a very
good way of like selecting your data if
you just care about
training on a subset of your
pre-training data for a given Downstream
task so I think there's been some yeah
some kind of
sign of life in that area
um so uh one interesting question from
uh from the class
um so uh kind of related to uh I guess
how we code the the models versus how
they're actually executed yeah
um so uh so obviously when we write our
python code especially you know in pi
Torchic it all gets compiled down to
like Cuda kernels and and whatnot
um so how does that kind of like affect
uh your your understanding of how like
how much information is actually like in
the in these code like do you have to
take into account like the 17 different
Cuda kernels that you're running through
throughout the throughout the year yeah
this is a great question uh so um I
actually oh yeah I've got to mention
that in the talk but basically I do have
a link in the slides if the slides
eventually get shared there is a link
but I am basing
um what was quite convenient was there
is a Transformer code Base called nncp
which is like no dependencies on
anything it's just just like a I think a
single C plus plus
self-contained Library which builds a
Transformer and trains it and has a few
tricks in it like it has drop out has
like data shuffling things and that is
like 200 kilobytes like whole
self-contained so that is a good like
I'm using that as a bit of a proxy
obviously it the size of f is kind of
hard to
know for sure
um it's easy to overestimate like if you
um packaged up your like python code
like and you're using pi torch or
tensorflow it's going to import all
these libraries which aren't actually
relevant you'll you might have like
something really big you might have like
hundreds of megabytes for a gigabyte of
all this like packaged stuff together
and you might think oh therefore the
description my Transformer is actually
like you know hundreds of megabytes so
I'm just it was convenient that someone
specifically tried to
um find out how small we can make this
and they did it by building it
um from scratch eventually
cool
um we also had a question about the
hutter prize
um which I believe you you had something
in your side so the question is uh so it
appears that our largest language models
can now compress things better than
um than than the than the best header
prize so your question is is this
challenge still relevant
um yeah could you actually use the
algorithm that you suggest
um for for the hunter price yeah I'll
tell you exactly
um I mean this is something I've talked
with Marcus Hunter about the hood
surprise is like actually asking people
to do exactly the right thing but the
main issue was they it was focused on
compressing quite a small amount of data
and that date that amount of data was
fixed 100 megabytes now a lot of this
kind of perceptual roadmap is like
there's been a huge amount of benefit in
increasing
the amount of data and compute in
simultaneous
um and that and and by doing that we're
able to like continue like this training
loss curve is like getting lower you're
like
um your compression rates improving so
I would say the prize itself has not
um has just not been fruitful in like
actually promoting compression and
instead what ended up being the
Breakthrough was kind of like Bert slash
gpt2 which I think
um it's steered people to the benefit of
simultaneously essentially adopting this
workflow without necessarily naming its
compression
um I think yeah I think the Benchmark
just due to the compute limitations it
also requires it's very like outdated
something like needs like 100 maximum of
100 CPUs or something for like 48 hours
so I think essentially it didn't end up
creating an amazing like AI algorithm
but it was just because it really
underestimated the benefit of compute
like compute memory all that stuff it
turns out that's a big part of the story
of building powerful models so does that
reveal something about our current large
data sets that you kind of need to see
all this data before you can start
compressing the rest of it well yeah I
think well the cool thing is like
because the compression is the integral
in theory if you could have some
algorithm which you could learn faster
like initially that would actually have
better compression and it would be
something that you would expect it as a
result therefore that would suggest it
would kind of be a more intelligent
system and yeah I think like having
better data efficiency
is something we should really think
about strongly and I think there's
actually quite a lot of potential core
research to try and learn more from less
data uh and right now we're in
especially a lot of the big Labs I mean
there's a lot of data out there to to
kind of collect so I think maybe people
have just prioritized for now like oh it
feels like it's almost almost kind of
like an endless real data so we just
keep adding more data but then I think
there's without a doubt going to be a
lot more research focused on making more
of the data that we have
right
I wonder if you can speculate a little
bit about what this starts to look like
in I guess images and video I think you
had a slider or two at the end where
um well like as you mentioned that uh if
your data is not super g-zippable
um then that maybe there's a lot of
noise and uh I believe
um and and my intuition may be wrong but
I believe that images and or certainly
images they they appear to be a lot
larger a lot bigger than
um than than text so that doesn't have
these properties I've got a few useful
thoughts on this okay so one is we
currently have a huge limitation in our
architecture which is a Transformer or
even just like a deep content and that
is that the architecture does not adapt
in any way to the information content of
its inputs so what I mean by that is if
you have
[Music]
um
even if we have a bite level sequence of
Text data but we just represent it as
the bytes of a utf-8 and then instead we
have a bpe tokenized sequence and it
contains the exact same information but
it's just 4X shorter sequence length uh
the Transformer will just spend four
times more compute on the byte level
sequence if it was fed it and it'll
spend four times Less on the bpe
sequence of this feather even though
they have the same information content
so we don't have some kind of algorithm
which could like kind of fan out and
then just like process the byte level
sequence with the same amount of
approximate compute
and I think that really hurts images
like if we had some kind of architecture
that could quite gracefully try and like
think at the frequency of like useful
for uh no matter whether it's looking at
high definition image or quite a low
definition image or it's looking at 24
kilohertz audio or 16 kilohertz audio
just like we do I think we're very
graceful with things like that we have
kind of
like very like selective attention-based
Vision we are able to like process audio
and kind of we're able to like have a
kind of our own internal kind of
thinking frequency that works for us and
this is just something that's like a
clear limitation in our architecture so
yeah right now if you just model pixel
level with a Transformer very wasteful
and it's not something
um that's like the optimal thing to do
right now but given there's a clear
limitation on our architecture it's
possible it's still the right thing to
do it's just we need to figure out how
to do it efficiently
so does that suggest that a model that
could
um you know switch between different
resolutions uh like at the one token and
time resolution that's important for
text versus the
um I don't know I think you mentioned
you know the 24 kilohertz of audio does
that suggest that a module that a model
like that would uh be able to compress
like different modalities better
um and have you know higher sensory yeah
that's I think it's it would be crazy to
write it off at this stage anyway I
think a lot of people assume like oh
pixel level modeling it just doesn't
make sense on some fundamental level but
it's hard to know that whilst we still
have a big uh kind of fundamental
blocker with our best architecture so
yeah I think it's I wouldn't write it
off anyway
so Michael is slacking me he wants me to
ask if you follow the S4 line of work
yeah
yeah I think that's a really important
architecture
sorry go on
yeah I I was just uh so S4 uh so okay so
I guess for for those for those
listening S4 has a property where
um it's it was designed explicitly for
long sequences
um and one of the uh early uh set of uh
you know driving applications was this
pixel pixel by pixel image
classification
um sequential cfar uh that they called
it
um and uh one of the interesting things
that S4 can do is actually switch from
um the these different uh resolutions by
um uh by changing essentially some the
the parameterization a little bit
um
so does that suggest you that like
something like S4 or something with a
different
um you know encoding would uh would have
these like implications for I don't know
being more intelligent or or being a
better compressor of these other
modalities or something like that yeah
so like on a broad brushstroke like S4
allows you to maybe have a much longer
context uh than attention without paying
the quadratic compute cost uh there are
still other I don't think it solves
everything but I think it seems like a
very very promising like piece of
architecture development
um I think other parts are like even
within your MLP like linears in your
MLPs which are actually for a large
language than most of your compute
um you really want to be spending well
I'm saying I don't know this for sure
but it feels like there should be a very
non-uniform allocation of compute uh
depending on what is easy to think about
what it's hard to think about
um and so yeah if there's a more natural
way of
there was a cool paper called calm which
uh it was about early exiting like
essentially when neural network or some
intermediate layer feels like it's it's
it's done enough compute and it can now
just like skip all the way to the end
that was kind of an idea in that regime
but like this kind of adaptive compute
theme I think it could be a really
really big
[Music]
um
like
breakthrough towards this if we think of
our own thoughts it's like very it's
very sparse very non-uniform
and uh you know maybe some of that stuff
is written in From Evolution but but
yeah having like this incredibly
homogenous uniform compute for every
token uh it doesn't quite feel right so
yeah I think S4 is very cool I think it
could be could help in this direction
for sure
interesting uh we did get one more
question from the class that I wanted to
get your opinion on so the question is
do you think compression research for
the sake of compression uh is important
for these I guess for these like
intelligent simple implications
um reacting a little bit to the comments
on the hudder prize
um and it sounds like the compression
capabilities of the foundation models
are kind of byproducts instead of the
primary goal when training them
yeah so this is what I think I think um
the compression objective is the only
training objective that I know right now
uh which is completely non-gameable and
has a very rigorous Foundation of why it
should help us create better and better
generalizing agents in a better
perceptual system
however we should be continually
evaluating models based on their
capabilities which is fundamentally what
we care about and so the compression
like metric itself is one of the most
like harsh alien metrics you can look at
it's just a number that means almost
nothing to us and actually just as that
number goes down like say or should I
say the compression rate goes up or the
kind of bits per character say go down
it's very unobvious what's going to
happen
um so you have to have other evals where
we can try and like predict the
emergence of new capabilities or track
them because those are the things that
fundamentally people care about uh but I
think people that either do research in
this area or study at study at
University it's prestigious as Stanford
should have a good understanding of why
all of this makes sense
um but I still but I do think yeah that
doesn't necessarily means it needs to
completely go in everything about this
every research and doing research for
the impression itself I didn't think
it's necessarily the right way to think
about it
um yeah hopefully that answers that
question
I wonder if
um that has implications for things like
training for more than one Epoch uh I
think somehow the field recently has
um uh arrived at the idea that you
should only you know see all your
training data once
um yeah I've got response to that so
actually training for more than one
Epoch is not um it's not like if you do
it literally yeah then it doesn't really
make sense from a compression
perspective because once you've finished
your epoch you can't count the log loss
of your second Epoch towards your
compression objective because a very
powerful model by that point if you did
it could just have like say users
retrieval let's memorize everything
you've seen and then it's just going to
get perfect performance from then on
that obviously is not creating a more
intelligent system but it might like
it'll minimize your training also make
you feel good about yourself
um so at the same time yeah training is
more than one Epoch can give you better
generalization what's happening
um
I think the way to think about it is the
ideal setup would be like in RL you have
this initial replay so you're going
through you're going through your Epoch
in theory like all you can count towards
your like compression score is your
prediction for the next held out piece
of training data but there's no reason
why you couldn't then actually chew up
and like spend more SGD steps on like
past data so I think in the compression
setup multi Epoch just looks like replay
essentially now in practice I think just
pragmatically it's easier to just train
with with multiple epochs
um you know so yeah I think I just want
to clear up like compression does not
it's not actually synonymous with only
training for one Epoch because you can
still do replay and essentially see your
data multiple times but it basically
says you can only like
score yourself for all of the
predictions which will let your next
batch of data have held out data that's
the only thing that's the fair thing
just came out of school
hopefully
so we're nearing the end of the hour so
I wanted to just give you a chance uh if
there's anything
um you know that you're excited about
coming out uh anything in the pipeline
that that you wanted to talk about and
just wanted to give you a chance to kind
of give a preview of what may be next in
this area uh and kind of uh what's
coming up and exciting for you
um
um okay
well
I think 2023
it doesn't need me to really sell it
very much I think it's going to be
pretty much like every week something
amazing is going to happen so
um if not every week then every two
weeks the pace of innovation right now
I'm sure as you're very aware is pretty
incredible I think there's going to be
lots of stuff
amazing stuff coming out from companies
in the Bay Area such as open AI uh and
around the world in in Foundation models
both in the development of stronger ones
but also this incredible amount of
Downstream research that there's just
such a huge community of people using
these things now tinkering with them
exploring capabilities so yeah I feel
like we're kind of in a in a cycle of
mass
um Innovation so I think yeah it's just
strap in and try not to get too
overwhelmed
yeah
it's a bit it's looking to be a very
exciting year
absolutely
right
um yeah so that brings us to the end of
the hour so I wanted to thank you Jack
again for coming on it was a very
interesting talk uh thanks of course
everybody who's listening online and in
the class for for your great questions
um if uh this Wednesday we're gonna have
Susan John from meta she's going to be
talking a little bit about the trials of
training uh opt 175 billion so that
would be very interesting for us to uh
to talk to her and hear about
um if you want to you can go to our
website
mlsys.stanford.edu to see the rest of
our schedule I believe we only have one
more week left
um so it's been it's been an exciting
quarter thank you of course everyone for
participating
um when with that we will uh wave
goodbye and say goodbye to YouTube
5.0 / 5 (0 votes)


Degenerative AI… The recent failures of "artificial intelligence" tech

Google CEO Sundar Pichai and the Future of AI | The Circuit
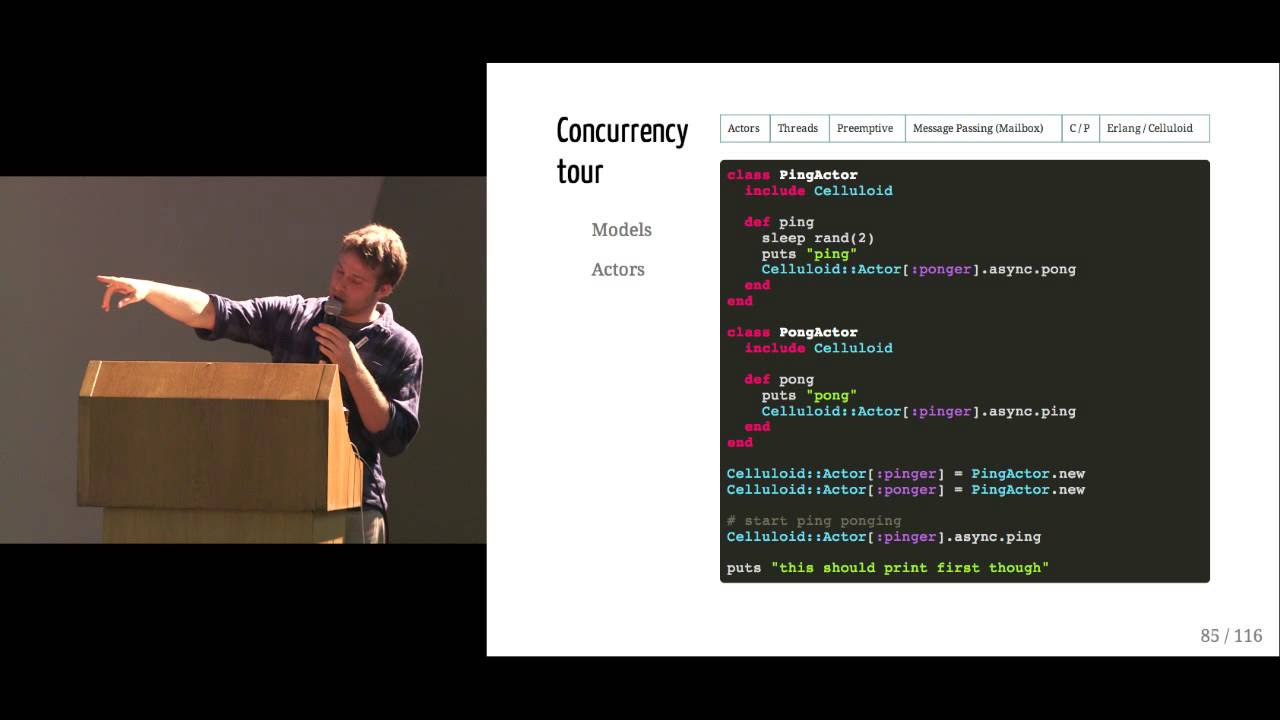
Shai Rosenfeld - Such Blocking, Very Concurrency, Wow

ChatGPT Can Now Talk Like a Human [Latest Updates]

OG Ads vs. CPAGrip: Navigating the Complex World of Affiliate Marketing Platforms

Why & When You Should Use Claude 3 Over ChatGPT