Simple Introduction to Large Language Models (LLMs)
Summary
TLDRThe video script offers an insightful journey into the world of artificial intelligence (AI), with a focus on large language models (LLMs). It explains that LLMs are neural networks trained on vast text data to understand and generate human-like language. The video traces the evolution of LLMs from the early Eliza model to modern giants like GPT-4, highlighting the transformative impact of AI on various industries. It delves into the workings of LLMs, including tokenization, embeddings, and the Transformer algorithm, which allows models to predict and generate language. The script also addresses the training process, emphasizing the importance of quality data and computational resources. Furthermore, it touches on fine-tuning pre-trained models for specific applications and the ethical considerations surrounding AI development, including bias, data copyright, and the potential for misuse. The video concludes by exploring the real-world applications of LLMs, current advancements like knowledge distillation and retrieval-augmented generation, and the future of AI, including self-fact-checking, multimodality, and improved reasoning abilities.
Takeaways
- 📚 Large Language Models (LLMs) are a type of neural network trained on vast amounts of text data, enabling them to understand and generate human-like text.
- 🧠 Neural networks, including LLMs, are designed to recognize patterns in data, simulating the human brain's functions, with a focus on natural language processing.
- 🚀 LLMs differ from traditional programming by teaching computers how to learn tasks rather than explicitly instructing them on what to do, offering a more flexible approach.
- 🖼️ Applications of LLMs include image recognition, text generation, creative writing, question answering, and programming assistance.
- ⚡ The evolution of LLMs began with the ELIZA model in 1966 and has accelerated with the introduction of the Transformer architecture in 2017, leading to models like GPT-3 with 175 billion parameters.
- 🌐 Training LLMs requires massive datasets, which can include web pages, books, and various text sources, emphasizing the importance of data quality to avoid biases and inaccuracies.
- ⏱️ The process of training LLMs is time-consuming and resource-intensive, involving data pre-processing, weight adjustment through prediction, and evaluation based on metrics like perplexity.
- 🔍 Fine-tuning allows pre-trained LLMs to be customized for specific use cases, making them more efficient and accurate for tasks like pizza order processing.
- 🤖 LLMs have limitations, including struggles with math, logic, reasoning, and the potential to propagate biases present in their training data.
- 🔮 Ethical considerations for LLMs involve issues related to data copyright, potential misuse for harmful acts, job displacement, and the future alignment of AI with human values.
- 🔬 Current advancements in LLMs include knowledge distillation, retrieval augmented generation, mixture of experts, multimodality, and improving reasoning abilities for more accurate and efficient models.
Q & A
What is the main focus of the video?
-The video focuses on large language models (LLMs), explaining how they work, their ethical considerations, applications, and the history and evolution of these technologies.
What is a large language model (LLM)?
-A large language model (LLM) is a type of neural network trained on vast amounts of text data, designed to understand and generate human-like language.
How do LLMs differ from traditional programming?
-Traditional programming is instruction-based, providing explicit commands to the computer, whereas LLMs teach the computer how to learn, making them more flexible and adaptable for a variety of applications.
What is the significance of the 'Transformers' architecture in the context of LLMs?
-The 'Transformers' architecture, introduced by Google DeepMind, is significant because it allows for more efficient training of LLMs, with features like self-attention that help the models better understand the context of words within a sentence.
What is the role of tokenization in LLMs?
-Tokenization is the process of splitting long text into individual tokens, which are essentially parts of words. This allows the model to understand each word individually and in relation to others, facilitating the model's comprehension of language.
How do embeddings contribute to LLMs?
-Embeddings are numerical representations of tokens that LLMs use to understand how different words are related to each other. They are stored in vector databases, which allow the model to predict the next word based on the previous words' embeddings.
What is fine-tuning in the context of LLMs?
-Fine-tuning involves taking pre-trained LLMs and adjusting them with additional data specific to a particular use case. This process results in a model that is better suited for specific tasks, such as pizza order processing.
What are some limitations of LLMs?
-LLMs have limitations such as struggles with math and logic, potential biases inherited from the training data, the risk of generating false information (hallucinations), and the high computational resources required for training and fine-tuning.
How can LLMs be applied in real-world scenarios?
-LLMs can be applied in various tasks including language translation, coding assistance, summarization, question answering, essay writing, translation, and even image and video creation.
What is knowledge distillation in the context of LLMs?
-Knowledge distillation is the process of transferring key knowledge from very large, cutting-edge models to smaller, more efficient models, making large language models more accessible and practical for everyday consumer hardware.
What are some ethical considerations surrounding LLMs?
-Ethical considerations include the use of potentially copyrighted material for training, the potential for models to be used for harmful acts like misinformation campaigns, the disruption of professional workforces, and the alignment of AI with human incentives and outcomes.
What advancements are being researched to improve LLMs?
-Current advancements include self-fact checking using web information, mixture of experts for efficient model operation, multimodality to handle various input types, improving reasoning ability by making models think step-by-step, and increasing context sizes with external memory.
Outlines
📚 Introduction to AI and Large Language Models (LLMs)
This paragraph introduces the video's purpose: to educate viewers on artificial intelligence (AI) and large language models (LLMs), even if they have no prior knowledge. It mentions the significant impact of AI on the world, particularly in the past year, with applications like chatbots. The video is a collaboration with AI Camp, a program for high school students learning about AI. LLMs are defined as neural networks trained on vast text data, contrasting with traditional programming, and are highlighted for their flexibility and ability to learn from examples. The potential applications of LLMs are also discussed.
🧠 How LLMs Work: The Technical Process
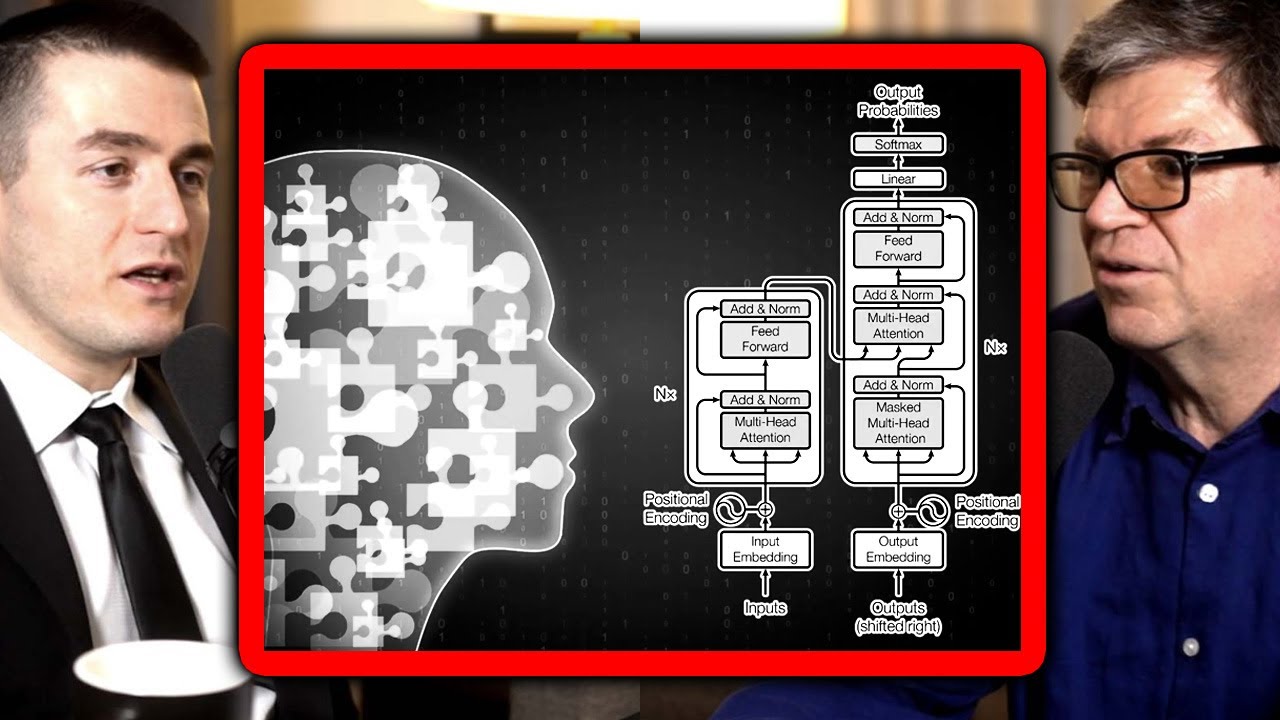
The paragraph delves into the three-step process of how LLMs operate: tokenization, embeddings, and Transformers. Tokenization involves breaking down text into individual tokens. Embeddings transform tokens into numerical vectors that represent words' meanings and relationships. Transformers use these vectors to predict the next word in a sequence, adjusting the model's weights for optimal output. The importance of vector databases in capturing word relationships is also emphasized, along with the role of multi-head attention in the Transformer algorithm.
📈 Training Large Language Models: Data and Resources
This section discusses the training process of LLMs, emphasizing the need for vast amounts of high-quality data. It covers the importance of data pre-processing and the computational resources required for training, including specialized hardware. The process involves feeding pre-processed text data into the model, which uses Transformers to predict the next word based on context. The model's effectiveness is evaluated using perplexity and reinforcement learning through human feedback. The video also touches on fine-tuning, which allows pre-trained models to be customized for specific applications.
🔍 Limitations and Challenges of LLMs
The paragraph addresses the limitations and challenges associated with LLMs, such as their struggles with math, logic, and reasoning, as well as issues with bias and safety. It mentions that LLMs are trained on human-created data, which can introduce biases and inaccuracies. The challenge of 'hallucinations,' where models generate incorrect information with confidence, is also highlighted. Additionally, the hardware-intensive nature of LLMs, the ethical concerns surrounding data use, and the potential for misuse are discussed.
🚀 Real-world Applications and Advancements in LLMs
The video outlines the diverse real-world applications of LLMs, including language translation, coding assistance, summarization, and creative writing. It also covers current research and advancements, such as knowledge distillation, which transfers knowledge from large models to smaller, more efficient ones, and retrieval augmented generation, which allows models to access external information. Ethical considerations are also discussed, including the impact on various professions, the potential for harmful use, and alignment with human values as AI becomes more sophisticated.
🔗 Conclusion and Further Resources
The final paragraph concludes the video by encouraging viewers to like and subscribe for more content on AI. It provides information about AI Camp, a program for students interested in AI, and invites viewers to explore additional AI-related videos for further learning. The call to action promotes engagement with the content and further education in the field of AI.
Mindmap
Keywords
💡Large Language Models (LLMs)
💡Neural Networks
💡Tokenization
💡Embeddings
💡Transformers
💡Fine-tuning
💡Bias
💡Ethical Considerations
💡Knowledge Distillation
💡Multimodality
💡Reasoning Ability
Highlights
Artificial intelligence and large language models (LLMs) have revolutionized the world with products like Chat GPT, affecting every industry and how people interact with technology.
LLMs are neural networks trained on vast amounts of text data, simulating human brain function to understand natural language.
Unlike traditional programming, LLMs teach computers how to learn, offering a more flexible approach for various applications.
LLMs are adept at tasks such as summarization, text generation, creative writing, question-answering, and programming.
The evolution of LLMs began with the Eliza model in 1966 and has advanced significantly with the introduction of the Transformers architecture in 2017.
GPT-3, released in 2020, gained public attention for its superior understanding of natural language, powering models like Chat GPT.
GPT-4, released in 2023, boasts 1.76 trillion parameters and uses a mixture of experts approach for specific use cases.
The process of LLMs involves tokenization, embeddings, and Transformers to understand and predict word sequences in natural language.
Vector databases help LLMs capture the relationship between words as vectors in multidimensional space, aiding in understanding semantics.
Training LLMs requires vast amounts of data, significant processing power, and is an expensive endeavor.
Fine-tuning allows pre-trained models to be customized for specific use cases, offering higher accuracy and efficiency.
AI Camp is a program that educates high school students on artificial intelligence, collaborating with this video's creation.
LLMs have limitations, including struggles with math, logic, reasoning, and the potential for bias and harmful outputs.
Ethical considerations for LLMs involve the use of copyrighted material, potential for misuse, and the impact on the workforce.
LLMs have a wide range of real-world applications, from language translation to coding assistance and creative tasks.
Current advancements include knowledge distillation, retrieval augmented generation, and efforts to improve reasoning and context sizes.
The future of LLMs may involve self-fact-checking, multimodal inputs, and alignment with human incentives for ethical AI development.
Transcripts
this video is going to give you
everything you need to go from knowing
absolutely nothing about artificial
intelligence and large language models
to having a solid foundation of how
these revolutionary Technologies work
over the past year artificial
intelligence has completely changed the
world with products like chat PT
potentially appending every single
industry and how people interact with
technology in general and in this video
I will be focusing on llms how they work
ethical cons iterations applications and
so much more and this video was created
in collaboration with an incredible
program called AI camp in which high
school students learn all about
artificial intelligence and I'll talk
more about that later in the video let's
go so first what is an llm is it
different from Ai and how is chat GPT
related to all of this llms stand for
large language models which is a type of
neural network that's trained on massive
amounts of text data it's generally
trained on data that can be found online
everything from web scraping to books to
transcripts anything that is text based
can be trained into a large language
model and taking a step back what is a
neural network a neural network is
essentially a series of algorithms that
try to recognize patterns in data and
really what they're trying to do is
simulate how the human brain works and
llms are a specific type of neural
network that focus on understanding
natural language and as mentioned llms
learn by reading tons of books articles
internet texts and there's really no
limitation there and so how do llms
differ from traditional programming well
with traditional programming it's
instruction based which means if x then
why you're explicitly telling the
computer what to do you're giving it a
set of instructions to execute but with
llms it's a completely different story
you're teaching the computer not how to
do things but how to learn how to do
things things and this is a much more
flexible approach and is really good for
a lot of different applications where
previously traditional coding could not
accomplish them so one example
application is image recognition with
image recognition traditional
programming would require you to
hardcode every single rule for how to
let's say identify different letters so
a b c d but if you're handwriting these
letters everybody's handwritten letters
look different so how do you use
traditional programming to identify
every single possible variation well
that's where this AI approach comes in
instead of giving a computer explicit
instructions for how to identify a
handwritten letter you instead give it a
bunch of examples of what handwritten
letters look like and then it can infer
what a new handwritten letter looks like
based on all of the examples that it has
what also sets machine learning and
large language models apart and this new
approach to programming is that they are
much more more flexible much more
adaptable meaning they can learn from
their mistakes and inaccuracies and are
thus so much more scalable than
traditional programming llms are
incredibly powerful at a wide range of
tasks including summarization text
generation creative writing question and
answer programming and if you've watched
any of my videos you know how powerful
these large language models can be and
they're only getting better know that
right now large language models and a in
general are the worst they'll ever be
and as we're generating more data on the
internet and as we use synthetic data
which means data created by other large
language models these models are going
to get better rapidly and it's super
exciting to think about what the future
holds now let's talk a little bit about
the history and evolution of large
language models we're going to cover
just a few of the large language models
today in this section the history of
llms traces all the way back to the
Eliza model which was from
1966 which was really the first first
language model it had pre-programmed
answers based on keywords it had a very
limited understanding of the English
language and like many early language
models you started to see holes in its
logic after a few back and forth in a
conversation and then after that
language models really didn't evolve for
a very long time although technically
the first recurrent neural network was
created in 1924 or RNN they weren't
really able to learn until 1972 and
these new learning language models are a
series of neural networks with layers
and weights and a whole bunch of stuff
that I'm not going to get into in this
video and rnns were really the first
technology that was able to predict the
next word in a sentence rather than
having everything pre-programmed for it
and that was really the basis for how
current large language models work and
even after this and the Advent of deep
learning in the early 2000s the field of
AI evolved very slowly with language
models far behind what we see today this
all changed in 2017 where the Google
Deep Mind team released a research paper
about a new technology called
Transformers and this paper was called
attention is all you need and a quick
side note I don't think Google even knew
quite what they had published at that
time but that same paper is what led
open AI to develop chat GPT so obviously
other computer scientists saw the
potential for the Transformers
architecture with this new Transformers
architecture it was far more advanced it
required decreased training time and it
had many other features like self
attention which I'll cover later in this
video Transformers allowed for
pre-trained large language models like
gpt1 which was developed by open AI in
2018 it had 117 million parameters and
it was completely revolutionary but soon
to be outclassed by other llms then
after that Bert was released beert in
2018 that had 340 million parameters and
had bir directionality which means it
had the ability to process text in both
directions which helped it have a better
understanding of context and as
comparison a unidirectional model only
has an understanding of the words that
came before the target text and after
this llms didn't develop a lot of new
technology but they did increase greatly
in scale gpt2 was released in early 2019
and had 2.5 billion parameters then GPT
3 in June of 2020 with 175 billion
paramet
and it was at this point that the public
started noticing large language models
GPT had a much better understanding of
natural language than any of its
predecessors and this is the type of
model that powers chat GPT which is
probably the model that you're most
familiar with and chat GPT became so
popular because it was so much more
accurate than anything anyone had ever
seen before and it was really because of
its size and because it was now built
into this chatbot format anybody could
jump in and really understand how to
interact act with this model Chad GPT
3.5 came out in December of 2022 and
started this current wave of AI that we
see today then in March 2023 GPT 4 was
released and it was incredible and still
is incredible to this day it had a
whopping reported 1.76 trillion
parameters and uses likely a mixture of
experts approach which means it has
multiple models that are all fine-tuned
for specific use cases and then when
somebody asks a question to it it
chooses which of those models to use and
then they added multimodality and a
bunch of other features and that brings
us to where we are today all right now
let's talk about how llms actually work
in a little bit more detail the process
of how large language models work can be
split into three steps the first of
these steps is called tokenization and
there are neural networks that are
trained to split long text into
individual tokens and a token is
essentially about 34s of a word so if
it's a shorter word like high or that or
there it's probably just one token but
if you have a longer word like
summarization it's going to be split
into multiple pieces and the way that
tokenization happens is actually
different for every model some of them
separate prefixes and suffixes let's
look at an example what is the tallest
building so what is the tallest building
are all separate tokens and so that
separates the suffix off of tallest but
not building because it is taking the
context into account and this step is
done so models can understand each word
individually just like humans we
understand each word individually and as
groupings of words and then the second
step of llms is something called
embeddings the large language models
turns those tokens into embedding
vectors turning those tokens into
essentially a bunch of numerical
representations of those tokens numbers
and this makes it significantly easier
for the computer to read and understand
each word and how the different words
relate to each other and these numbers
all correspond with the position in an
embeddings Vector database and then the
final step in the process is
Transformers which we'll get to in a
little bit but first let's talk about
Vector databases and I'm going to use
the terms word and token interchangeably
so just keep that in mind because
they're almost the same thing not quite
but almost and so these word embeddings
that I've been talking about are placed
into something called a vector database
these databases are storage and
retrieval mechanisms that are highly
optimized for vectors and again those
are just numbers long series of numbers
because they're converted into these
vectors they can easily see which words
are related to other words based on how
similar they are how close they are
based on their embeddings and that is
how the large language model is able to
predict the next word based on the
previous words Vector databases capture
the relationship between data as vectors
in multidimensional space I know that
sounds complicated but it's really just
a lot of numbers vectors are objects
with a magnitude and a direction which
both influence how similar one vector is
to another and that is how llms
represent words based on those numbers
each word gets turned into a vector
capturing semantic meaning and its
relationship to other words so here's an
example the words book and worm which
independently might not look like
they're related to each other but they
are related Concepts because they
frequently appear together a bookworm
somebody who likes to read a lot and
because of that they will have
embeddings that look close to each other
and so models build up an understanding
of natural language using these
embeddings and looking for similarity of
different words terms groupings of words
and all of these nuanced relationships
and the vector format helps models
understand natural language better than
other formats and you can kind of think
of all this like a map if you have a map
with two landmarks that are close to
each other they're likely going to have
very similar coordinates so it's kind of
like that okay now let's talk about
Transformers mat Matrix representations
can be made out of those vectors that we
were just talking about this is done by
extracting some information out of the
numbers and placing all of the
information into a matrix through an
algorithm called multihead attention the
output of the multi-head attention
algorithm is a set of numbers which
tells the model how much the words and
its order are contributing to the
sentence as a whole we transform the
input Matrix into an output Matrix which
will then correspond with a word having
the same values as that output Matrix so
basically we're taking that input Matrix
converting it into an output Matrix and
then converting it into natural language
and the word is the final output of this
whole process this transformation is
done by the algorithm that was created
during the training process so the
model's understanding of how to do this
transformation is based on all of its
knowledge that it was trained with all
of that text Data from the internet from
books from articles Etc and it learned
which sequences of of words go together
and their corresponding next words based
on the weights determined during
training Transformers use an attention
mechanism to understand the context of
words within a sentence it involves
calculations with the dot product which
is essentially a number representing how
much the word contributed to the
sentence it will find the difference
between the dot products of words and
give it correspondingly large values for
attention and it will take that word
into account more if it has higher
attention now now let's talk about how
large language models actually get
trained the first step of training a
large language model is collecting the
data you need a lot of data when I say
billions of parameters that is just a
measure of how much data is actually
going into training these models and you
need to find a really good data set if
you have really bad data going into a
model then you're going to have a really
bad model garbage in garbage out so if a
data set is incomplete or biased the
large language model will be also and
data sets are huge we're talking about
massive massive amounts of data they
take data in from web pages from books
from conversations from Reddit posts
from xposts from YouTube transcriptions
basically anywhere where we can get some
Text data that data is becoming so
valuable let me put into context how
massive the data sets we're talking
about really are so here's a little bit
of text which is 276 tokens that's it
now if we zoom out that one pixel is
that many tokens and now here's a
representation of 285 million tokens
which is
0.02% of the 1.3 trillion tokens that
some large language models take to train
and there's an entire science behind
data pre-processing which prepares the
data to be used to train a model
everything from looking at the data
quality to labeling consistency data
cleaning data transformation and data
reduction but I'm not going to go too
deep into that and this pre-processing
can take a long time and it depends on
the type of machine being used how much
processing power you have the size of
the data set the number of
pre-processing steps and a whole bunch
of other factors that make it really
difficult to know exactly how long
pre-processing is going to take but one
thing that we know takes a long time is
the actual training companies like
Nvidia are building Hardware
specifically tailored for the math
behind large language models and this
Hardware is constantly getting better
the software used to process these
models are getting better also and so
the total time to process models is
decreasing but the size of the models is
increasing and to train these models it
is extremely expensive because you need
a lot of processing power electricity
and these chips are not cheap and that
is why Nvidia stock price has
skyrocketed their revenue growth has
been extraordinary and so with the
process of training we take this
pre-processed text data that we talked
about earlier and it's fed into the
model and then using Transformers or
whatever technology a model is actually
based on but most likely Transformers it
will try to predict the next word based
on the context of that data and it's
going to adjust the weights of the model
to get the best possible output and this
process repeats millions and millions of
times over and over again until we reach
some optimal quality and then the final
step is evaluation a small amount of the
data is set aside for evaluation and the
model is tested on this data set for
performance and then the model is is
adjusted if necessary the metric used to
determine the effectiveness of the model
is called perplexity it will compare two
words based on their similarity and it
will give a good score if the words are
related and a bad score if it's not and
then we also use rlf reinforcement
learning through human feedback and
that's when users or testers actually
test the model and provide positive or
negative scores based on the output and
then once again the model is adjusted as
necessary all right let's talk about
fine-tuning now which I think a lot of
you are going to be interested in
because it's something that the average
person can get into quite easily so we
have these popular large language models
that are trained on massive sets of data
to build general language capabilities
and these pre-trained models like Bert
like GPT give developers a head start
versus training models from scratch but
then in comes fine-tuning which allows
us to take these raw models these
Foundation models and fine-tune them for
our specific specific use cases so let's
think about an example let's say you
want to fine tuna model to be able to
take pizza orders to be able to have
conversations answer questions about
pizza and finally be able to allow
customers to buy pizza you can take a
pre-existing set of conversations that
exemplify the back and forth between a
pizza shop and a customer load that in
fine- tune a model and then all of a
sudden that model is going to be much
better at having conversations about
pizza ordering the model updates the
weights to be better at understanding
certain Pizza terminology questions
responses tone everything and
fine-tuning is much faster than a full
training and it produces much higher
accuracy and fine-tuning allows
pre-trained models to be fine-tuned for
real world use cases and finally you can
take a single foundational model and
fine-tune it any number of times for any
number of use cases and there are a lot
of great Services out there that allow
you to do that and again it's all about
the quality of your data so if you have
a really good data set that you're going
to f- tune a model on the model is going
to be really really good and conversely
if you have a poor quality data set it's
not going to perform as well all right
let me pause for a second and talk about
AI Camp so as mentioned earlier this
video all of its content the animations
have been created in collaboration with
students from AI Camp AI Camp is a
learning experience for students that
are aged 13 and above you work in small
personalized groups with experienced
mentors you work together to create an
AI product using NLP computer vision and
data science AI Camp has both a 3-week
and a onewe program during summer that
requires zero programming experience and
they also have a new program which is 10
weeks long during the school year which
is less intensive than the onewe and
3-we programs for those students who are
really busy AI Camp's mission is to
provide students with deep knowledge and
artificial intelligence which will
position them to be ready for a in the
real world I'll link an article from USA
Today in the description all about AI
camp but if you're a student or if
you're a parent of a student within this
age I would highly recommend checking
out AI Camp go to ai- camp.org to learn
more now let's talk about limitations
and challenges of large language models
as capable as llms are they still have a
lot of limitations recent models
continue to get better but they are
still flawed they're incredibly valuable
and knowledgeable in certain ways but
they're also deeply flawed in others
like math and logic and reasoning they
still struggle a lot of the time versus
humans which understand Concepts like
that pretty easily also bias and safety
continue to be a big problem large
language models are trained on data
created by humans which is naturally
flawed humans have opinions on
everything and those opinions trickle
down into these models these data sets
may include harmful or biased
information and some companies take
their models a step further and provide
a level of censorship to those models
and that's an entire discussion in
itself whether censorship is worthwhile
or not I know a lot of you already know
my opinions on this from my previous
videos and another big limitation of
llms historically has been that they
only have knowledge up into the point
where their training occurred but that
is starting to be solved with chat GPT
being able to browse the web for example
Gro from x. aai being able to access
live tweets but there's still a lot of
Kinks to be worked out with this also
another another big challenge for large
language modelss is hallucinations which
means that they sometimes just make
things up or get things patently wrong
and they will be so confident in being
wrong too they will state things with
the utmost confidence but will be
completely wrong look at this example
how many letters are in the string and
then we give it a random string of
characters and then the answer is the
string has 16 letters even though it
only has 15 letters another problem is
that large language models are EXT
extremely Hardware intensive they cost a
ton to train and to fine-tune because it
takes so much processing power to do
that and there's a lot of Ethics to
consider too a lot of AI companies say
they aren't training their models on
copyrighted material but that has been
found to be false currently there are a
ton of lawsuits going through the courts
about this issue next let's talk about
the real world applications of large
language models why are they so valuable
why are they so talked about about and
why are they transforming the world
right in front of our eyes large
language models can be used for a wide
variety of tasks not just chatbots they
can be used for language translation
they can be used for coding they can be
used as programming assistants they can
be used for summarization question
answering essay writing translation and
even image and video creation basically
any type of thought problem that a human
can do with a computer large language
models can likely also do if not today
pretty soon in the future now let's talk
about current advancements and research
currently there's a lot of talk about
knowledge distillation which basically
means transferring key Knowledge from
very large Cutting Edge models to
smaller more efficient models think
about it like a professor condensing
Decades of experience in a textbook down
to something that the students can
comprehend and this allows smaller
language models to benefit from the
knowledge gained from these large
language models but still run highly
efficiently on everyday consumer
hardware and and it makes large language
models more accessible and practical to
run even on cell phones or other end
devices there's also been a lot of
research and emphasis on rag which is
retrieval augmented generation which
basically means you're giving large
language models the ability to look up
information outside of the data that it
was trained on you're using Vector
databases the same way that large
language models are trained but you're
able to store massive amounts of
additional data that can be queried by
that large language model now let's talk
about the ethical considerations and
there's a lot to think about here and
I'm just touching on some of the major
topics first we already talked about
that the models are trained on
potentially copyrighted material and if
that's the case is that fair use
probably not next these models can and
will be used for harmful acts there's no
avoiding it large language models can be
used to scam other people to create
massive misinformation and
disinformation campaigns including fake
images fake text fake opinions and
almost definitely the entire White
Collar Workforce is going to be
disrupted by large language models as I
mentioned anything anybody can do in
front of a computer is probably
something that the AI can also do so
lawyers writers programmers there are so
many different professions that are
going to be completely disrupted by
artificial intelligence and then finally
AGI what happens when AI becomes so
smart and maybe even starts thinking for
itself this is where we have to have
something called alignment which means
the AI is aligned to the same incentives
and outcomes as humans so last let's
talk about what's happening on The
Cutting Edge and in the immediate future
there are a number of ways large
language models can be improved first
they can fact check themselves with
information gathered from the web but
obviously you can see the inherent flaws
in that then we also touched on mixture
of experts which is an incredible new
technology which allows multiple models
to kind of be merged together all fine
tune to be experts in certain domains
and then when the actual prompt comes
through it chooses which of those
experts to use so these are huge models
that actually run really really
efficiently and then there's a lot of
work on multimodality so taking input
from voice from images from video every
possible input source and having a
single output from that there's also a
lot of work being done to improve
reasoning ability having models think
slowly is a new trend that I've been
seeing in papers like orca too which
basically just forces a large language
model to think about problems step by
step rather than trying to jump to the
final conclusion immediately and then
also larger context sizes if you want a
large language model to process a huge
amount of data it has to have a very
large context window and a context
window is just how much information you
can give to a prompt to get the output
and one way to achieve that is by giving
large language models memory with
projects like mgpt which I did a video
on and I'll drop that in the description
below and that just means giving models
external memory from that core data set
that they were trained on so that's it
for today if you liked this video please
consider giving a like And subscribe
check out AI Camp I'll drop all the
information in the description below and
of course check out any of my other AI
videos if you want to learn even more
I'll see you in the next one
5.0 / 5 (0 votes)

【人工智能】万字通俗讲解大语言模型内部运行原理 | LLM | 词向量 | Transformer | 注意力机制 | 前馈网络 | 反向传播 | 心智理论

Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus, & 1 GW Datacenters
Can LLMs reason? | Yann LeCun and Lex Fridman

ChatGPT Can Now Talk Like a Human [Latest Updates]

Ollama Embedding: How to Feed Data to AI for Better Response?

Why & When You Should Use Claude 3 Over ChatGPT