How to accelerate in Splunk
Summary
TLDR本视频深入讲解了Splunk中加速数据处理的三种方式:报告加速、摘要索引和数据模型加速。首先介绍了报告加速的基本原理,即通过预先计算并存储摘要数据来加快搜索速度。随后,探讨了摘要索引的概念,即将搜索结果输出到另一个索引中以提高效率。最后,详细说明了数据模型加速的优势,特别是使用tstats命令进行数据模型加速的方法,强调了它相较于普通stats函数在速度和性能上的显著优势。视频通过实际操作和示例,向观众展示了如何有效利用这些技术来优化Splunk的数据处理性能。
Takeaways
- 🔍 Splunk加速可通过报告加速、摘要索引和数据模型加速三种方式实现。
- ⚡ tstats命令比常规stats函数更强大、更快,用于优化Splunk搜索效率。
- 📊 报告加速通过在后台创建基于报告结果的摘要来加快搜索速度。
- 🔄 只有包含转换命令的搜索才能进行报告加速。
- 📈 摘要索引通过将搜索结果输出到另一个索引来实现加速,这个过程类似于索引的嵌套。
- 🔗 使用collect命令可以将搜索结果输出到摘要索引中,以减少搜索数据量,提高搜索速度。
- 🚀 数据模型加速被认为是三种加速方式中最优的选择。
- 🔧 tstats命令与数据模型加速紧密相关,可以高效查询统计信息。
- 📋 数据模型加速分为临时的ad hoc加速和持久的persistent加速两种类型。
- 🔑 对于安全运营中心(SOC)分析师来说,tstats命令在创建相关性搜索以触发显著事件时尤其有用。
Q & A
Splunk中加速报告的条件是什么?
-在Splunk中,为了资格进行报告加速,搜索必须包含一个转换命令。
为什么数据模型加速在Splunk中被认为是最佳选择?
-数据模型加速被认为是最佳选择,因为它通过优化和加速搜索查询来提高性能和效率,尤其是在处理大量数据时。
什么是摘要索引,它是如何工作的?
-摘要索引是一种加速方法,通过将常规搜索的结果输出到另一个索引(即摘要索引)来工作,这样可以减少数据量,从而加快搜索速度。
为什么tstats命令比常规的stats命令更强大和更快?
-tstats命令更强大和更快,因为它是为了在加速的数据模型上运行而优化的,它可以直接在时间序列索引文件(TSIDX)上执行统计查询,从而提高性能。
什么是数据模型加速中的持久和临时两种方式?
-在数据模型加速中,持久方式是指通过创建持久的加速数据汇总来实现加速,而临时方式是指仅在使用数据透视编辑器时临时加速数据。
为什么在编辑摘要索引的搜索时不直接修改父搜索命令?
-在编辑摘要索引的搜索时,不直接修改父搜索命令是为了确保原始数据集的搜索不受影响,同时能够将新数据继续发送到摘要索引。
为什么摘要索引可以使仪表板面板运行得更快?
-摘要索引可以使仪表板面板运行得更快,因为它减少了搜索数据的量,只对预先汇总和索引化的数据进行搜索,从而加快了搜索速度。
什么情况下应该考虑使用tstats命令?
-在需要极高性能的情况下,尤其是在安全操作中心(SOC)进行事件检测时,应该考虑使用tstats命令,以确保快速响应。
什么是TSIDX文件,它在Splunk中扮演什么角色?
-TSIDX文件代表时间序列索引文件,它们用于在Splunk中加速搜索查询,特别是在使用加速数据模型时,只搜索这些文件而不是原始数据。
在Splunk中实现加速的三种方式是什么?
-在Splunk中实现加速的三种方式是报告加速、摘要索引和数据模型加速。
Outlines
📈 报告加速与t stats命令入门
这一部分介绍了Splunk中加速的概念,包括报告加速、摘要索引和数据模型加速三种方式。报告加速是通过在后台运行进程来构建基于报告结果的摘要,使得搜索更快。为了进行报告加速,搜索必须包含转换命令。通过访问设置中的“搜索、报告和警报”,可以查看并编辑加速报告的选项。摘要索引被视为一种不太被推荐的加速方式,尽管它对某些用例有用。这部分强调了t stats命令的重要性,这是一个比标准stats命令更快更强大的统计工具,特别是在处理加速数据时。
🔍 摘要索引的实践应用
详细讲解了如何使用摘要索引来加速Splunk搜索。通过创建一个新的索引来作为摘要索引,并使用collect命令将搜索结果输出到这个新索引中,可以显著提高搜索速度。摘要索引仅包含被发送到它的数据子集,因此搜索这个更小的数据集可以更快完成。此外,还介绍了如何在仪表板面板中应用摘要索引来提高效率,特别是在处理缓慢加载的面板时。通过示例展示了将搜索结果重定向到摘要索引和在仪表板中使用这些索引的过程。
🚀 数据模型加速与t stats命令高级应用
探讨了数据模型加速的两种方式:即时(ad hoc)和持久(persistent),以及t stats命令在持久数据模型加速中的应用。即时加速仅适用于枢轴表编辑器,而持久加速则通过构建基于多个TS idx文件的摘要来优化搜索速度。提到了如何为数据模型加速设置并使用t stats命令来提高搜索的效率。最后,以一个实际示例结束,展示了如何使用t stats命令来检索和分析特定数据模型中的数据。
🔎 t stats命令深度解析
通过一个具体例子深入分析了t stats命令的应用,包括构建查询、识别和调查不明数据源。展示了如何利用t stats命令根据用户和应用程序的数据来构建统计查询,以及如何针对特定查询结果进行进一步的深入分析。这部分不仅强调了t stats命令在处理大量数据时的效率和强大功能,还展示了如何在遇到不确定或未知结果时进行有效的问题解决。
Mindmap
Keywords
💡Splunk
💡加速
💡t stats命令
💡报告加速
💡摘要索引
💡数据模型加速
💡transforming命令
💡collect命令
💡TS idx文件
💡SI stats命令
Highlights
Introduction to acceleration and the power of the t stats command in Splunk.
Explanation of how acceleration can improve search efficiency in Splunk.
Overview of the three ways to implement acceleration in Splunk: report acceleration, summary indexing, and data model acceleration.
Detailed guide on report acceleration and its prerequisites.
Step-by-step instructions on enabling report acceleration and its impact on search speed.
Introduction to summary indexing as a method of acceleration.
How to use the collect command for summary indexing to optimize Splunk searches.
Example use case of summary indexing for speeding up dashboard panel loading.
Explanation of how summary indexing reduces search times by creating a smaller dataset.
Introduction to data model acceleration as the preferred method for speed optimization.
Differences between ad hoc and persistent data model acceleration.
How t stats command utilizes TS idx files for faster data retrieval.
Demonstration of building a t stats command with a focus on specific fields.
Example of investigating unusual data using the t stats command.
Importance of data model acceleration for security analysts in Splunk Enterprise Security.
Transcripts
in this one we are going to cover
acceleration and Splunk and we're also
going to cover a critical command t
stats but it would kind of be pointless
to just jump off and start showing you t
stats off the bat without first
understanding how acceleration can be
invoked and then we will definitely get
into t stats and why it's more powerful
faster than regular stats function and
to do that like I said we're going to
cover acceleration first acceleration in
Splunk can be implemented in one of
three ways acceleration of reports
summary indexing and the acceleration of
data models and the acceleration of data
models will probably always be your best
bet someone please try and prove me
wrong so starting with report
acceleration when you accelerate a
report Splunk software runs in the
background a process that then builds a
summary based on the results returned by
that report when you run the search it
runs against the summary rather than the
full index because the summary is
smaller than the full index and contains
precomputed summary data relevant to
what that search was the search should
complete much quicker than it did when
you first ran it let me just show you
what I
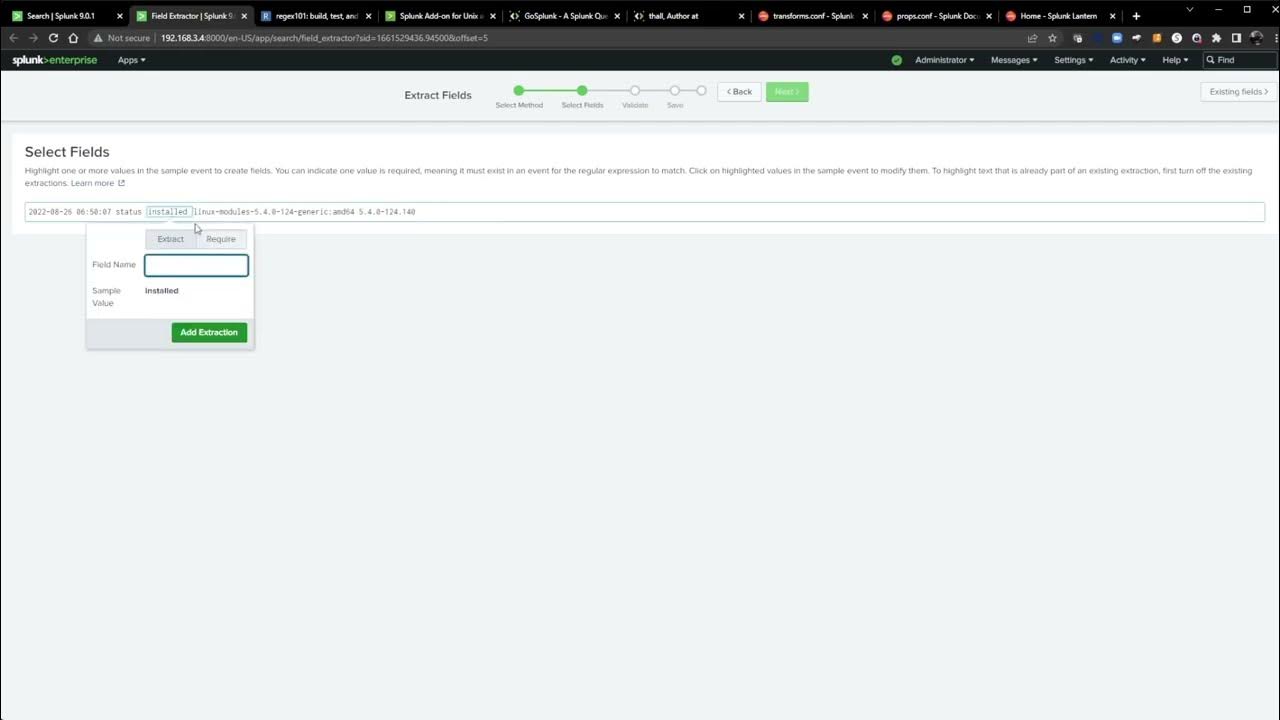
mean first in order to qualify for
acceleration it has to be including a
transforming command we can go to
settings searches reports and alerts and
take a look at a few examples so if we
open one that doesn't have a
transforming command like the wire shark
one here we can click edit and notice
that there is no option to accelerate it
that means that this search is not
formatted and it's not meeting the
criteria to become accelerated as you
can see there are no transforming
commands present in that search but if
we go back and we click on one that does
have a transforming search in it we can
see the edit acceleration and edit
summary index button are
present we will open this one in new tab
run it and see that the transforming
command present is
stats so we can go ahead and click edit
and edit the acceleration this is just a
checkbox saying I'm going to accelerate
the report and the summary range when
you set your summary range this is the
specific length and time that you want
the data to be accelerated then your
report will run as accelerated and it
will become more
efficient so you can just set the day
here
but for now I'm just going to leave it
as is and press cancel we'll come back
to that
later so that kind of covers report
acceleration in nutshell it's very
simple and if it fits your use case go
ahead and do it next we will move into
the second way to accelerate in Splunk
which is summary indexing honestly I'm
not a fan of this method as it kind of
just gets like index Inception as you'll
see but a lot of people actually do use
it and find it very relevant and very
helpful for the use cases so clearly I'm
missing something major here but I
usually just roll with creating um an
accelerated data model and leveraging t
stats but it I would be remissed if I
didn't cover summary indexing as well
because I've seen I've seen so many
people use it in the past so we can dive
in basically what you do with summary
indexing is you build your normal search
and then you can output those results to
another index using the collect command
and when you do that you're going to
Output that search results and you're
going to collect it into another index
that other index is going to be your
summary index you have to create that
summary index call it summary underscore
whatever you're summarizing or what you
will remember and then you can use that
index to search against and that is the
name summary indexing and it will only
contain the other small sets of data
results that you are sending to it with
the collect command so you know air
quotes I'm doing doing faster it summary
indexing is faster because there's less
data to search um because it's already
being searched by that primary search
from the other main index in the
original search you built but let me
stop trying to explain it with words and
we'll just show it in the demo actually
a good use case for this is to change
your dashboard panels if you find that
your dashboard panels are starting to
run slow so we're actually going to do
it for that use case so I'm going to
find a dashboard to edit I'll go into my
dashboards and home Dash I'll just work
with that one that's
fine we can click into it and this is
what we would do to find information
about our log levels and executables
running so here you would put in what
log level you want information on and it
would pass the token to the first panel
let's not work with the token panel
let's work with the second panel for
executables so this is a output of all
the executables that are running and you
can click into it and view the events
related to them but let's go ahead and
open it in a search here we can see it
already has a transforming command of
stats that we covered earlier and it
outputs all of my executables running on
my computer for whatever my time picker
all time so we're going to do as I
mentioned before is and send this to a
new index that we had created that will
act as our summary index so I'm going to
a pipe collect and then the index that
I've previously created so you will have
to create a new index that was going to
act that is going to act as your summary
index before you do this I called it
summary uncore
executables we can go ahead and run this
and by running this it now takes the
results of those events and sends them
to that new summary index of summary
executables so now that index has become
populated with the events that were
generated from our original
search and if we wanted to take take a
look notice we have almost 400,000
events here we can copy this and search
on this index that we just
created paste it
in search over 24 hours because I just
populated that index and boom it cuts it
down to 189 events only the ones that
are applicable to executables running on
my
machine so summary index searches run
faster because they're searching a
smaller data set and that one just
Narrows down the results based off what
you decide to send to it can go back to
the main search here and I'm going to
copy
this and if this is something that
you're going to want to do then you're
also going to want to cover the SI
command
family and one of the commands that we
have is Si stats probably the most
common one that you will use this just
takes it to the next level of the normal
stats command and now you have the
summary indexing SI version of stats so
the command knows to pick it up and work
with the and it knows it's working with
a summary index set of data so it will
go even faster than if you were to do it
with regular
stats we can take a look at the time
that this search took to
run and it's 432
seconds and if we go back into our
search and reports and we edit our first
search now bear with me this is where
people get very confused we have a
scheduled search that's set to run
acting as a report this right here is
the Parent Command what we want to do
with this parent search parent parent
set of uh parameters that we are giving
Splunk is send it to keep running on our
Crown schedule or however often we have
it set but also collect it to our new
summary index we don't want to change
this command here to our index equals
summary
executables
because that will not be querying the
actual data set that we need from our
correct parent indexes I'll show you
where to put the index equals summaries
executables in a moment but when you're
editing the current search you're only
going to add the collect command at the
end because we still need to generate
that new data that's coming in from our
data sources from those indexes that's
relevant to your Splunk environment so
when editing the search we're only going
to put in the pipe collect index and the
summary index that we want to send it to
this will now run on a cron and that
cron will run this search and that
search will populate that summary index
over time go ahead and save it it's
accelerated now we go back to our
Command that we
created to query our summary index we
can copy this go back to our
dashboard and and
edit and then the search we're going to
tell our dashboard to make it more more
efficient and run faster is if we edit
the search we're now going to take this
Parent Command that we that is used to
run the scheduled search or the KRON and
populate that dashboard we're now going
to pull that out and input our new
command that we built with our summary
index so we will copy this one and paste
it into the dashboard panel this is
critical because if you do have
dashboard panels that are taking forever
to populate summary indexing can be very
useful in this really Niche use case so
I'll paste in our new search that's only
querying that smaller data set in the
summary
index and save it
off now that dashboard panel is going to
be Wick it fast go ahead and save it and
you can do this to as many dashboard
panels that would fit your use case or
any kind of data source that needs to
run faster or any panels that are just
acting slow if we open this in a search
now you can see we are now leveraging
our summary indexing to generate our
results for our dashboard panel that's
uh some reindexing sorry for that
headache but a lot of people get
confused on which one needs to go where
and as long as you think about what the
command is doing and where your actual
data is getting inputed to during injust
to what index you should be able to keep
it straight just fine let me go ahead
and clean some of this up and we will
move into our last way to invoke
acceleration in Splunk which is
leveraging a data model and so far if I
would rank report acceleration I would
put it above the summary indexing option
but if you can leverage summary indexing
in this way maybe I would put it above
report acceleration it all kind of
depends but like I said I I'm going to
rank data model acceleration as number
one so we can go ahead and get into that
and cover the tats command so there are
two types of acceleration you can do
with data models ad hoc and persistent
ad hoc means you are using the pivot
editor and it's temporary and it's only
usable with pivot so that's about all
the time I'm going to spend talking
about the ad hack way to invoke
acceleration with data models next up we
have the persistent way this is where
tats can be used and this makes it so
that there are specific summaries of
multiple tsdx files that are being
leveraged to optimize
speed TS idx files stands for time
series index files so let's get into
some examples of persistent data model
acceleration and of course you got to be
admin to accelerate it or at least have
the permission granted to you to
accelerate your data models go back into
uh search and
Reporting all right and we're going to
head over to the index of web n I'm just
joking that's Terri terrible all right
we can go into settings data models and
I think for this one I'm going to pick
on the authentication data
model and here we have our breakdown of
the data model and the components to it
if we scroll to the bottom these are the
fields that I'm going to be working with
when you run an acceleration Splunk will
build an acceleration summary based on
the Range that you set so what does this
mean it means that the range of the data
it will take on a new form of TS idx
files and crank up your search speeds
when you have your index of data there
are only two parts to that index the
first part is the raw data files and the
second part is the TS idx files so when
you accelerate a data model in Splunk
you tell it to basically ignore
searching of all that bulky raw data in
the index and only search those TS idx
files that are in there and they're a
lot smaller and I'm not going to get
into the granularity of how they differ
and how they're leveraged and how Splunk
knows to search them but just push the I
believe button there and believe me when
I say when you're using
acceleration it's only going to leverage
your TS idx
files and when you leverage tstats that
will be performing those statistical
queries on your TS idx files and as a
side note the tstats command is most
commonly used with Splunk Enterprise
security so that's pretty much for all
your sock analysts out there because
anytime we are creating a new
correlation search to trigger a notable
event we want to First consider if we
can utilize the tats command because we
would want those searches that are
leveraging detections in the stock to be
as fast as possible so that there is no
delay for the analyst triaging those
searches I'm going to take app action
destination and
user so now that I know what Fields I'm
going to use to search I can start
populating out my tstats command
leveraging the data model so I'll keep
that open for reference and I'll pop
open a new tab and start building it out
so I'm going to start with t stats and
then I'm just going to values out some
of those leverage
Fields so I'm going to start with
authentication that's the name of the
data model and then the field of
app and I'll call it source
application I'm also going to pull
Authentication action and I'll leave it
as
action just make sure it's the correct
field here parent authentication doapp
yep
dot action okay so I think I got it
authentication
doaction I'm just going to call it
action notice my colors are not popping
up so I've definitely typed something
wrong
here I forgot a double quote whoops okay
call it
action and I will take
destination as I'll just leave it t
from and I will count from the data
model of
authentication and I'm going to do it by
user so authentication do
user
all right we can go ahead and run this
and I'll just do it over the past
month that was my dog
sneezing and I would expect to only see
me so this one number eight Lo internal
unknown only makes me a little bit
nervous and I have no populating values
for sours application so definitely
spelled something wrong there's no tea
man got to have the tea live for it okay
rerun it and we see okay yeah it's an
internal application that I have but
let's say I didn't have that field
populate and I saw unknown and I was
super paranoid um let's just go ahead
and
investigate those two counts there so
unknown application I'm just going to
copy this because I'm lazy and I'll open
it up in a new tab and I'll say from
data model authentication because those
are where the events are populating
from
and I will do just a
search and give it the
app copy
pasta and user was unknown so user
equals unknown and I'll run this over
all
time well 30
days and let's see what we get
yes that is my internal
app from my own
laptop okay well I just wanted to dive
in because didn't know what that was so
clearly my own uh app of spunk
instrumentation the built-in app is is
doing something
here okay we can move
on
5.0 / 5 (0 votes)