【人工智能】万字通俗讲解大语言模型内部运行原理 | LLM | 词向量 | Transformer | 注意力机制 | 前馈网络 | 反向传播 | 心智理论
Summary
TLDRThis video explores the inner workings of large language models (LLMs) in an accessible way, focusing on their training and architecture. It explains how LLMs use word vectors and Transformer layers to understand and predict language, leveraging massive datasets and computational power. The video also highlights how models like GPT-3 and GPT-4 have evolved to perform complex reasoning tasks, sparking debates on their true understanding of language. It concludes by emphasizing the importance of empirical performance despite the complexity and mystery of these models' inner workings.
Takeaways
- 🤖 Large language models (LLMs) have become extremely popular, but few people understand their internal workings.
- 📚 The article by Tim Lee and Sean Trott explains LLMs in simple terms, focusing on word vectors, the Transformer architecture, and training processes.
- 🌐 Word vectors represent words as points in a high-dimensional space, capturing semantic relationships and allowing complex operations.
- 🌐 The Transformer architecture, introduced by Google in 2017, is the backbone of models like ChatGPT, processing words individually and in parallel.
- 🔍 Attention mechanisms in Transformers allow words to share information based on relevance, clarifying ambiguous contexts.
- 📈 Larger LLMs with more parameters and training data perform better on complex tasks, demonstrating improved reasoning abilities.
- 🧠 The training process involves predicting the next word in a sequence, adjusting parameters through forward and backward passes.
- 📊 The performance of LLMs correlates with scale: more data, parameters, and computational power lead to better results.
- 🤔 Some LLMs show signs of advanced reasoning, such as theory of mind, though debates remain about whether this reflects true understanding.
- 💡 The success of LLMs suggests that prediction is a fundamental aspect of both artificial and biological intelligence.
- 🌐 Despite their capabilities, LLMs are still not fully understood, and ongoing research aims to unravel their internal mechanisms.
Q & A
What is the primary purpose of the article discussed in the video?
-The primary purpose of the article is to explain the internal workings of large language models (LLMs) in a way that minimizes the use of complex mathematical concepts and technical jargon, making the information accessible to a broader audience.
Why are large language models considered different from traditional software?
-Large language models are different from traditional software because they are based on neural networks trained on billions of words, rather than being programmed with explicit step-by-step instructions by human engineers. This makes their internal workings less transparent and harder to fully understand.
What is a word vector, and why is it important for language models?
-A word vector is a long list of numbers (often hundreds or thousands of dimensions) used to represent a word in a way that captures its semantic relationships with other words. It is important because it allows language models to perform operations and inferences that are not possible with simple text representations.
How do transformers contribute to the functioning of large language models?
-Transformers are the building blocks of large language models like ChatGPT. They process input text by updating the hidden states of words through attention mechanisms and feed-forward layers, allowing the model to understand context and predict the next word accurately.
What is the role of attention mechanisms in transformers?
-Attention mechanisms in transformers allow words to share information with each other based on their relevance to the context. This helps the model resolve ambiguities, understand relationships between words, and focus on important parts of the input text.
Why do large language models require massive amounts of data for training?
-Large language models require massive amounts of data to learn the complex patterns and relationships in human language. The more data they are trained on, the better they become at predicting the next word and understanding context, leading to improved performance in various language tasks.
What is the significance of the increasing size of language models like GPT-3 and GPT-4?
-The increasing size of language models allows them to capture more nuanced and abstract relationships in language, leading to better performance in tasks that require reasoning and understanding. Larger models also tend to exhibit more advanced capabilities, such as higher accuracy in predicting the next word and improved performance in complex reasoning tasks.
How do researchers study the internal workings of large language models?
-Researchers study the internal workings of large language models by analyzing the behavior of attention heads, examining the patterns learned by feed-forward layers, and conducting experiments to understand how different parts of the model contribute to its predictions. However, fully understanding these models remains a challenging and ongoing process.
What is the 'clever Hans effect' in the context of large language models?
-The 'clever Hans effect' refers to the phenomenon where a model appears to perform a task correctly but is actually relying on subtle cues or biases in the data rather than true understanding. This can lead to misleading results and highlights the difficulty in fully interpreting the capabilities of large language models.
Why is the next-token prediction task effective for training large language models?
-Next-token prediction is effective because it allows models to learn from vast amounts of unlabelled text data by predicting the next word in a sequence. This task leverages the inherent structure and predictability of language, enabling models to capture complex linguistic patterns without the need for explicit human annotations.
How do large language models handle words with multiple meanings?
-Large language models handle words with multiple meanings by using context-dependent word vectors. Depending on the surrounding words and context, the model generates different vector representations for the same word, allowing it to distinguish between meanings such as 'bank' as a financial institution versus 'bank' as a riverbank.
Outlines
📚 Introduction to Large Language Models and Word Vectors
This paragraph introduces the topic of large language models (LLMs) and their growing popularity. It mentions an article by Tim Lee and Sean Trott, which explains LLMs in simple terms. The paragraph discusses how LLMs like ChatGPT are based on neural networks trained on billions of words, making their internal workings difficult to fully understand. The authors aim to explain the basics of LLMs without complex math or jargon, starting with word vectors. It explains how word vectors represent words as points in a high-dimensional space, capturing semantic relationships between words. The example of geographic coordinates is used to illustrate how similar words are placed closer together in this space. The paragraph also touches on the evolution of word vectors, starting with Google's word2vec project in 2013, which captured various linguistic relationships but also reflected biases in language.
🔍 Understanding Context and Polysemy in Language Models
This paragraph delves into how language models handle polysemy and homonyms, where words have multiple meanings. It explains that advanced models like ChatGPT can represent the same word with different vectors based on context, distinguishing between meanings like 'bank' as a financial institution or a riverbank. The paragraph highlights the importance of context in resolving ambiguities in natural language, such as pronoun reference or word sense disambiguation. It introduces the concept of hidden states in neural network layers, where each layer processes input vectors and adds context to better predict the next word. The example of the Transformer architecture is used to show how layers progressively refine word meanings, with early layers focusing on grammar and later layers on broader contextual understanding. The paragraph also mentions the vast number of dimensions in modern word vectors, which allow for richer semantic representation.
🌐 The Role of Attention Mechanisms in Transformers
This paragraph focuses on the attention mechanism within Transformer models, which enables words to share information based on relevance. It explains how each word creates query and key vectors to find and transfer information to other words. The example of 'John wants his bank to cash the check' illustrates how attention heads can match pronouns with their antecedents. The paragraph discusses the parallel operation of multiple attention heads, each focusing on different tasks like resolving polysemy or linking proper nouns. It mentions the complexity of models like GPT-3, which has 96 layers with 96 attention heads each, performing thousands of attention operations per prediction. The paragraph also references research on GPT-2, showing how different attention heads contribute to predicting the next word in a sentence, highlighting the intricate and layered nature of these models.
📈 The Function and Complexity of Feed-Forward Layers
This paragraph explores the feed-forward layers in large language models, which process word vectors independently to predict the next word. It explains the structure of these layers, using the example of GPT-3's massive number of neurons and weights, totaling billions of parameters. The paragraph discusses how feed-forward layers use pattern matching to identify specific sequences or themes in text, with later layers recognizing more abstract patterns. It mentions research showing how these layers can perform vector operations to make analogies or convert word forms. The paragraph also highlights the role of feed-forward layers in remembering information not present in the input text, contrasting with the attention mechanism's focus on retrieving context from the input.
🔍 Training Large Language Models without Explicit Labels
This paragraph explains the training process of large language models, which involves predicting the next word in a sequence without needing labeled data. It contrasts this with traditional machine learning methods that require explicit labels. The paragraph uses an analogy of adjusting water taps to illustrate how models adjust their parameters through forward and backward passes, with billions of calculations required for each training example. It discusses the exponential growth in model size and complexity, from GPT-1 to GPT-4, and how larger models achieve better performance on various tasks. The paragraph also touches on the models' ability to develop advanced reasoning capabilities, such as theory of mind, as a byproduct of their increasing scale and training data.
🧠 The Evolution of Reasoning and Cognitive Abilities in LLMs
This paragraph examines the development of reasoning abilities in large language models, such as GPT-3 and GPT-4. It references studies showing how these models have improved in tasks like theory of mind, where they can infer beliefs and intentions based on context. The paragraph discusses the debate over whether these models truly understand language or merely mimic patterns, highlighting the philosophical questions surrounding artificial intelligence. It mentions examples like GPT-4's ability to generate code for drawing a unicorn, suggesting that models may learn implicit knowledge about the world from text. The paragraph concludes by emphasizing the importance of evaluating models' empirical performance, even if their internal workings remain opaque.
Mindmap
Keywords
💡Large Language Models
💡Word Vectors
💡Transformer
💡Attention Mechanism
💡Hidden States
💡Training
💡Parameters
💡Polysemy and Homonyms
💡Forward and Backward Pass
💡Theory of Mind
Highlights
Introduction of Tim Lee and Sean Trott as authors who explain large language models using minimal math and jargon.
ChatGPT's impact on the tech industry and the world, with millions of users but limited understanding of its inner workings.
Explanation of how large language models predict the next word using vast amounts of text data.
The concept of word vectors as a way for language models to represent and understand words.
Google's word2vec project in 2013, which popularized the idea of word vectors and their ability to capture semantic relationships.
How word vectors can reflect biases in human language, such as gender or cultural stereotypes.
The role of context in understanding polysemous words and homonyms, and how language models handle these complexities.
Introduction to the Transformer architecture as the foundation of models like ChatGPT.
How attention mechanisms in Transformers allow words to share information and resolve ambiguities.
The use of multiple attention heads in Transformers to perform parallel processing and focus on different tasks.
The feed-forward layer's role in predicting the next word based on contextual information processed by attention heads.
The massive scale of models like GPT-3, with billions of parameters and thousands of dimensions in word vectors.
The training process of large language models using self-supervised learning without explicit labeled data.
The evolution of GPT models from GPT-1 to GPT-4, with increasing scale and improved performance in complex reasoning tasks.
Examples of large language models demonstrating advanced reasoning abilities, such as theory of mind and creative problem-solving.
The philosophical debate about whether large language models truly understand language or merely mimic patterns.
Transcripts
大家好这里是最佳拍档我是大飞
这半年时间啊
大语言模型无疑是最火爆的
但是我们呢一直没有好好的去讲一下
大语言模型内部究竟是如何工作的
不过最近啊
蒂姆·李(Tim Lee)和肖恩·特洛特(Sean Trott)
联合编写了一篇文章
用最少的数学知识和术语
对大语言模型进行了解释
先简单对文章作者做一下介绍啊
蒂姆·李曾经任职于科技媒体Ars Technica
他最近呢也推出了一份newsletter
《Understanding AI》
主要是探讨人工智能的工作原理
而肖恩特洛特呢
是加里福尼亚大学圣迭戈分校的助理教授
主要研究人类语言理解和语言模型
好了以下是我翻译的文章内容
咱们看看当你看完视频之后
究竟能否理解大语言模型的内部机制
全文呢几乎没有太复杂的数学概念、公式和运算
所以我觉得呢
对于很多初学者来说也是非常友好的
当ChatGPT在去年秋天推出的时候
在科技行业乃至全世界的范围内引起了轰动
当时呢机器学习的研究人员
已经研发了多年的大语言模型
但是普通大众并没有十分的关注
也没有意识到他们会变得有多强大
如今呢几乎每个人都听说过大语言模型了
并且呢有数千万人用过他们
但是了解他们工作原理的人并不多
你可能听说过
训练大语言模型是用来预测下一个词
而且呢他们需要大量的文本来实现这一点
但是一般的解释呢通常也就是止步于此
他们究竟如何预测下一个词的细节
往往被大家视为一个深奥的谜题
其中一个原因是
大语言模型的开发方式非常与众不同
一般的软件呢都是由人类工程师所编写的
他们为计算机提供明确的逐步的指令
而相比之下
ChatGPT是建立在一个
使用了数十亿个语言词汇
进行训练的神经网络之上
因此呢到现在为止
地球上也没有人完全理解
大语言模型的内部工作原理
研究人员正在努力尝试理解这些模型
但是这是一个需要数年
甚至几十年才能够完成的缓慢过程
不过呢专家们确实对这些系统的工作原理
已经有了不少的了解
我们的目的呢是将这些知识开放给广大的受众
我们将在不涉及技术术语或者高级数学的前提下
努力解释已知的大语言模型内部的工作原理
我们将从解释词向量Word Vector开始
这是语言模型表示和推理语言的一种令人惊讶的方式
然后我们将深入探讨Transformer
它是构建ChatGPT等模型的基石
最后呢我们将解释这些模型是如何训练的
并且探讨为什么要使用庞大的数据量
才能够获得良好的性能
要了解语言模型的工作原理
首先需要了解他们如何来表示单词
人类呢是用字母序列来表示英文单
词的比如说C-A-T cat表示猫
而语言模型呢使用的是一个叫做词向量的
一长串数字的列表
比如说这是一种将猫表示为向量的方式
完整的向量长度呢实际上有300个数字
那为什么要用这么复杂的表示方法呢
这里边啊有个类比
比如说华盛顿区位于北纬38.9度西经77度
我们可以用向量表示法表示为
华盛顿区的坐标是38.9和77
纽约的坐标呢是40.7和74
伦敦的坐标呢是51.5和0.1
巴黎的坐标呢是48.9和-2.4
这对于推理空间关系很有用
你可以看出纽约离华盛顿区很近
因为坐标中的38.9接近于40.7
而77呢接近于74
同样呢巴黎离伦敦也很近
但是巴黎离华盛顿区很远
大语言模型呢正是采用了类似的方法
每个词向量代表了词空间word space中的一个点
具有相似含义的词的位置互相会更为接近
比如说在向量空间中
与猫cat最接近的词就包括dog、kitten和pet
用实数向量来表示像cat这样的单词
它的一个主要优点就是
数字能够进行字母无法进行的运算
单词太过于复杂了
无法只使用二维来表示
因此大语言模型使用了具有数百甚至数千维度的向量空间
人们无法想象具有如此高维度的空间
但是计算机完全可以对它进行推理
并产生有用的结果
几十年来研究人员一直在研究词向量
但是这个概念呢真正引起关注的是在2013年
那时候Google公布了word2vec项目
Google分析了从Google新闻中收集的数百万篇文档
为了找出哪些单词倾向于出现在相似的句子中
随着时间的推移
一个经过训练的神经网络
学会了将相似类别的单词
比如说dog和cat
放置在向量空间中的相邻位置
Google的词向量还具有另一个有趣的特点
你可以使用向量运算来推理单词
比如说
Google研究人员取出biggest的向量
减去big的向量再加上small的向量
与结果向量最接近的词就是smallest
也就是说
你可以使用向量运算来进行类比
在这个例子中
big与biggest的关系类似于small与smallest的关系
Google的词像量还捕捉到了许多其他的关系
比方说瑞士人与瑞士这类似于柬埔寨人与柬埔寨
巴黎于法国类似于柏林与德国
不道德的与道德的类似于可能的与不可能的
mouse与mice类似于dollar与dollars
男人与女人类似于国王与女王
等等等等
因为这些向量是从人们使用语言的方式中构建的
所以他们反映了许多存在于人类语言中的偏见
比如说在某些词项链的模型中
医生减去男人再加上女人等于护士
减少这种偏见呢是一个很新颖的研究领域
尽管如此
词向量是大语言模型的一个基础
他们编码了词与词之间微妙但是重要的关系信息
如果一个大语言模型学到了关于cat的一些知识
比方说他有时候会去看兽医
那同样的事情呢很可能也适用于kitten或者dog
如果模型学到了关于巴黎和法国之间的关系
比方说他们使用了同一种语言
那么柏林和德国以及罗马和意大利的关系
很可能也是一样的
但是像这样简单的词向量方案
并没有捕获到自然语言的一个重要事实
那就是一个单词通常有多重的含义
比如说
单词bank可以指金融机构或者是河岸
或者以这两个句子为例
在这两个句子中magazine的含义相关但是又有不同
约翰拿起的是一本杂志
而苏珊为一家出版杂志的机构工作
当一个词有两个无关的含义时
语言学家称之为同音异义词(homonyms)
当一个词有两个紧密相关的意义时
比如说这个magazine
语言学家呢称之为多义词(polysemy)
像ChatGPT这样的大语言模型
能够根据单词出现的上下文
用不同的向量来表示同一个词
有一个针对于机构的bank的向量
还有一个针对于河岸的bank的向量
有一个针对于杂志的magazine的向量
还有一个针对于杂志社的magazine的向量
对于多义词的含义啊 正如你预想的那样
大语言模型使用的向量会更相似
而对于同音异义词的含义
使用的向量呢则不太相似
到目前为止
我们还没有解释语言模型是如何做到这一点的
我们很快呢会进入这个话题
不过详细说明这些向量表示
这对于理解大语言模型的工作原理非常重要
在传统软件的设计中数据处理呢是明确的
比如说你让计算机计算2+3
关于2、加号或者3的含义呢都不存在歧义问题
但是自然语言中的歧义
远不止于同音异义词和多义词
比方说顾客请修理工修理他的车
这句话中his是指顾客还是指修理工
教授催促学生完成她的家庭作业中
her是指教授还是学生
第三句中的flies
到底是一个动词在空中飞
还是一个名词果蝇呢
在现实中人们会根据上下文来解决这类歧义
但是并没有一个简单或者明确的规则
相反呢这就需要理解关于这个世界的实际情况
你需要知道
修理工经常会修理顾客的汽车
学生呢通常会完成自己的家庭作业
而水果呢通常不会飞
因此呢词向量为大语言模型提供了一种灵活的方式
用来在特定段落的上下文中
表示每个词的准确含义
现在让我们来看看
他们是究竟如何做到这一点的
ChatGPT最初版本背后的GPT-3
模型是由数十个神经网络层组成的
因为输入文本中的每个词会对应着一个向量
所以这些神经网络中的每一层
都会接受一系列的向量作为输入
并添加一些信息来帮助澄清这个词的含义
从而更好的预测接下来可能出现的词
让我们从一个简单的示例说起
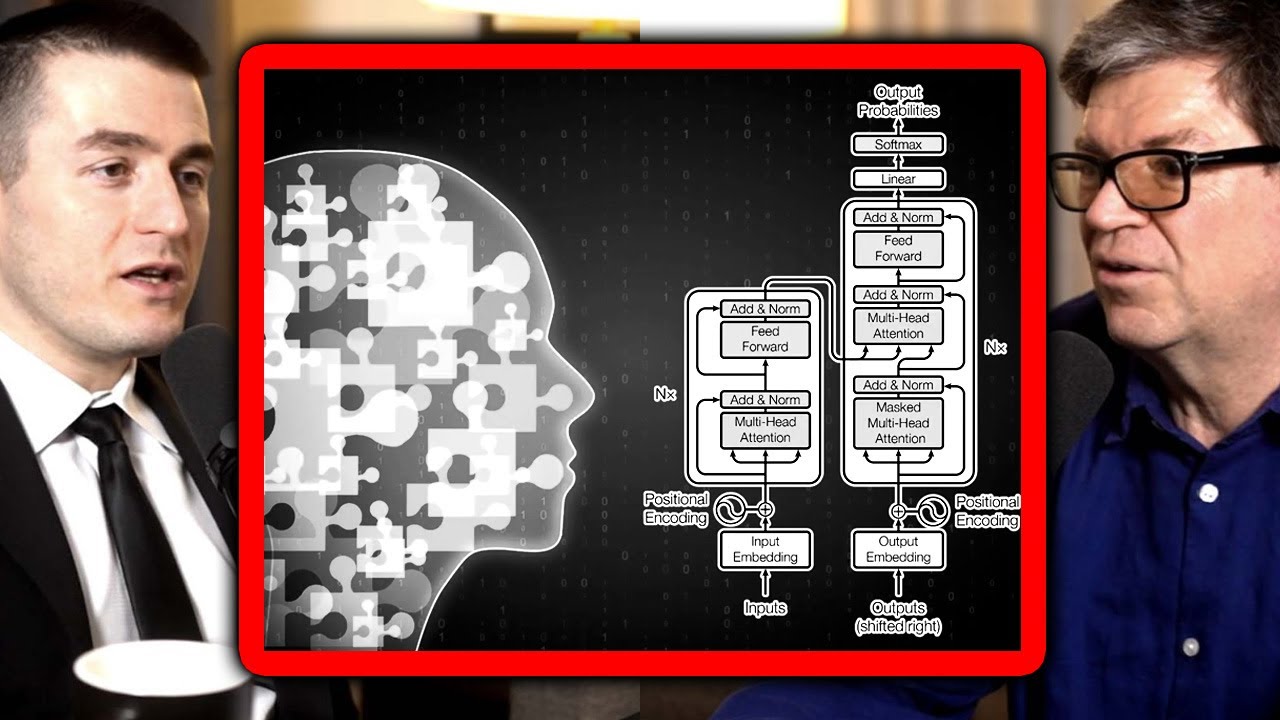
大语言模型的每个层呢都是一个Transformer
2017年Google在一篇里程碑式的论文中
首次介绍了这种神经网络结构
在这张图的底部
模型的输入文本是John wants his back to catch the
翻译过来就是约翰想让他的银行兑现
这些单词呢被表示为word2vec的风格的向量
并传提给第一个Transformer
这个Transformer确定了wants和cash都是动词
我们用小括号内的红色文本表示这个附加的上下文
但实际上模型会通过修改词向量的方式来存储这个信息
这种方式对于人类来说很难解释
这些新的向量被称为隐藏状态hidden state
并传递给下一个Transformer
第二个transformer添加了另外两个上下文信息
他澄清了bank是金融机构financial institution
而不是河岸
并且his是指代John的代词
第二个Transformer产生了另一组隐藏状态向量
这组向量反映的是这个模型之前所学习的所有信息
这张图表描绘的是一个纯粹假想的大语言模型
所以大家呢不要对细节过于较真
真实的大圆模型往往有更多的层
比如说最强大的GPT-3版本有96层
有研究表明
前几层的神经网络会专注于理解句子的语法
并且解决上面所表示的歧义
而后面的层则致力于对整个文本段落的高层次的理解
比如说当大语言模型阅读一篇短篇小说的时候
他似乎会记住关于故事角色的各种信息
包括性别和年龄、与其他角色的关系
过去和当前的位置个性和目标等等
研究人员呢并不完全了解
大语言模型是如何跟踪这些信息的
但是从逻辑上来讲
模型在各层之间传递信息时候
必须通过修改隐藏状态的向量来实现
现代大语言模型中的向量维度极为庞大
这有利于表达更为丰富的语义信息
比如说GPT-3最强大的版本使用了有12,288个维度的词向量
也就是说每个词是由一个包含了12,288个的数字序列表示
这比Google在2013年提出的word2vec的方案要大20倍
你可以把所有这些额外的维度看作是GPT-3
可以用来记录每个词的上下文的一种暂存空间Scratch space
较早的层所做的信息笔记可以被后来的层读取和修改
从而使得模型逐渐加深对整篇文章的理解
因此假设我们将之前的图表改为描述一个96层的语言模型
来解读一个1,000字的故事
那么第60层可能会包含一个用于John的向量
带有一个表示为主角、男性、娶了谢利尔唐、纳德的表弟
来自于明尼斯达州、目前在博伊希、试图找到他丢失的钱包
这样一整套的括号注释
同样呢所有这些以及更多的事实
都会以一个包含12,288个数字列表的形式进行编码
这些数字都对应着这个词John
或者说这个故事中的其他词
比方说谢利尔、唐纳德、伯伊希、钱包
或者是其他的词
他们的某些信息也会被编码在12,288维的向量中
这样做的目标是让网络的第96层和最后一层
输出一个包含所有必要信息的隐藏状态
从而来预测下一个单词
现在我们来谈谈每个Transformer内部发生的情况
Transformer在更新输入段落的每个单词的隐藏状态时候
有两个处理过程
第一个呢是在注意力的步骤中
词汇会观察周围
查找具有相关背景并彼此共享信息的其他的词
第二呢在前馈步骤中
每个词会思考之前注意力步骤中收集到的信息
并尝试预测下一个词
当然了执行这些步骤的是整个网络
而不是个别的单词
但是我们用这种方式来表述是为了强调
Transformer是以单词作为这一个分析的基本单元
而不是整个句子或者是段落
这种方法使得大语言模型能够充分的利用
现代GPU芯片的大规模并行处理能力
它还可以帮助大语言模型
扩展到包含成千上万个词的长段落
而这两个方面都是早期大语言模型所面临的挑战
你可以将注意力机制
看作是单词之间的一个撮合服务
每个单词呢都会制作一个检查表称为查询向量
来描述他寻找的词的特征
每个词呢还会制作一个检查表称为关键向量
描述他自己的特征
神经网络通过将每个关键向量与每个查询向量进行比较
通过计算他们的点积来找到最佳匹配的单词
一旦找到匹配项
他就会从产生关键向量的单词
把相关信息传递给产生查询向量的单词
比如说在前面的部分中
我们展示了一个假想的Transformer模型
他发现在“John wants his bank to cash the”这个句子中
his指的就是John
在系统内部
过程可能是这个样子
his的查询向量可能会有效的表示为
我正在寻找一名描述男性的名词
而John的关键向量可能会有效的表述为
我是一个描述男性的名词
然后网络就会检测到这两个向量是匹配的
并将关于John的向量信息转移给his的向量
每个注意力层都有几个注意力头
这意味着这个信息交换的过程在每一层上会并行的进行多次
每个注意力头呢都会专注于不同的任务
比方说其中一个注意力头
可能会将代词与名词进行匹配
另外一个注意力头
可能会处理解析类似于bank这样的一词多义的含义
第三个注意力头
可能会将Joe Biden这样的两个单词连接在一起
诸如这类的注意力头经常会按照顺序来操作
一个注意力层中的注意力操作结果
会成为下一层中的另一个注意力头的输入
事实上呢
我们刚才列举的每个任务可能都需要多个注意力头
而不仅仅是一个
GPT-3的最大版本呢有96个层
每个层有96个注意力头
因此每次预测一个新词的时候
GPT-3将执行9,216个注意力的操作
以上内容
我们展示了注意力头工作的方式的一个理想化的版本
现在让我们来看一下关于真实语言模型内部运作的研究
去年研究人员在Redwood research研究了GPT-2
即ChatGPT的前身
对于“When Mary and John went to the store, John gave a drink to”
这个段落翻译过来就是当玛丽和约翰去商店
约翰把一杯饮料给了
预测这句话下一个单词的过程
GPT-2预测的下一个单词呢是Mary玛丽
研究人员就发现
有三种类型的注意力头对这个预测做出了贡献
第一种
三个被他们称为名称移动头的注意力头
(Name Mover Head)
将信息呢从Marry向量复制到了最后的输入向量
也就是to这个词所对应的向量
GPT-2使用这个最右向量中的信息来预测下一个单词
那么神经网络又是如何来决定Marry是正确的复制词呢
通过GPT-2的计算过程进行逆向的推导
科学家们发现了一组他们称之为主语抑制头的四个注意力头(Subject Inhibition Head)
它们标记了第二个John向量
阻止了名称移动头来复制John这个名字
主语抑制头又是如何知道不应该复制John的呢
团队进一步向后推导
发现了他们称为重复标记头的两个注意力头
(Duplicate Token Heads)
他们将第二个John向量
标记为第一个John向量的重复副本
这帮助主语抑制头来决定不应该复制John
简而言之
这9个注意力头使得GPT-2能够理解
“John gave a drink to John”是没有意义的
而选择“John gave a drink to Mary”
这个例子呢也侧面说明了
要完全理解大语言模型会有多么困难
由五位研究人员组成的Redwood团队
曾经发表了一篇25页的论文
解释了他们是如何识别和验证这些注意力头的
然而即使他们完成了所有这些工作
我们离对于为什么GPT-2决定
预测Mary作为下一个单词的全面解释
还有很长的路要走
比如说模型是如何知道下一个单词应该是某个人的名字
而不是其他类型的单词
很容易想到在类似的句子中
Mary不会是一个好的下一个预测词
比如说
在句子“when Mary and John went to the restaurant, John gave his keys to”这个句子中
逻辑上呢下一个词应该是“the valet”
即代客停车员
假设计算机科学家们进行了充足的研究
也许他们可以揭示和解释
GPT-2推理过程中的其他步骤
最终呢他们可能能够全面理解GPT-2
是如何决定Marry是句子最可能的下一个单词
但是这可能需要数个月甚至数年的努力
才能够理解一个单词的预测情况
而ChatGPT背后的语言模型
GPT-3和GPT-4 比GPT-2呢更加的庞大和复杂
相比于Redwood团队研究的简单句子
他们能够完成更复杂的推理任务
因此完全解释这些系统的工作将是一个巨大的项目
人类不太可能在短时间内完成
我们继续回到注意力头的部分
当注意力头在词向量之间传输信息之后
前馈网络会思考每个词向量并且尝试预测下一个词
在这个阶段单词之间没有交换任何的信息
前馈层会独立的去分析每个单词
但是前馈层可以访问之前由注意力头复制的任何信息
这个是GPT-3最大版本的前馈层结构
其中绿色和紫色的圆圈表示神经元
他们是计算其输入加权和的数学函数
前馈层之所以强大是因为它有大量的连接
在图上呢我们使用了三个神经元作为输出层
六个神经元作为隐藏层
绘制出了这个网络
但是GPT-3的前馈层要大得多
它的输出层有12,288个神经元
对应模型的12,288维的词向量
每个神经元有49,152个输入值
也就是每个神经元有49,152个权重参数
而隐藏层呢有49,152个神经元
每个神经元呢有12,288个输入值
也就是每个神经元有12,288个权重参数
这意味着每个前馈层有49,152乘以12,288
再加上12,288乘以49,152个
约等于12亿个权重参数
并且有96个前馈层
那加起来就是12亿乘以96等于1,160亿个参数
这相当于具有1,750亿参数的GPT-3将近2/3的参数量
在2020年的一篇论文中
来自特拉维夫大学的研究人员就发现
前馈层通过模式匹配进行工作
即隐藏层中的每个神经元
都能够匹配输入文本中的特定模式
下面呢是一个16层版本的GPT-2中
一些神经元匹配的模式
第一层的神经元匹配以substitutes结尾的词序列
第6层的神经元匹配与军事有关
并且以base或者bases结尾的词序列
第13层的神经元匹配以时间范围结尾的序列
比如说在下午3点到7点之间
或者从周五晚上7点到
第16层的神经元匹配与电视节目相关的序列
比如说原始的NBC日间版本已存档
或者说时间延迟使该集的观众增加了57%
没错正如我们所看到的
越是在后面的层中模式会变得越来抽象
早期的层会倾向于匹配特定的单词
而后期的层则匹配属于更广泛语言类别的短语
比如说电视节目或者说时间间隔
这部分呢其实很有意思
因为正如我们之前所说的
前馈层呢每次只能检查一个单词
因此当将训练原始的NBC日间版本已存档
分类为与电视相关的时候
他只能访问已存档这个词的向量
而不是NBC或者是日间等等词汇
可以推断出前馈层之所以可以判断已存档
是电视节目相关序列的一部分
是因为注意力头之前已经将上下文的信息
移到了已存档archived的这个词的向量中
当一个神经元与其中一个模式匹配的时候
他就会向这些词像量中添加信息
虽然这些信息呢并不总是很容易解释的
但是在许多情况下
你可以将它视为对下一个词的临时的预测
我们之前讨论过Google的word2vec的研究
它可以使用向量运算来进行类比的推理
比如说柏林减去德国加上法国等于巴黎
布朗大学的研究人员就发现前馈层
有时候会使用这种准确的方法来预测下一个单词
比如说他们研究了GPT-2对以下提示的回应
问题法国的首都是什么回答巴黎
问题波兰的首都是什么回答华沙
这个团队研究了一个包含24层的GPT-2的版本
在每个层之后
布朗大学的科学家们去探测模型
观察他对下一个token的最佳预测
在前15层最高的可能性的猜测
是一个看似于随机的单词
在第16层和第19层之间
模型开始预测下一个单词是波兰
不正确但是越来越接近于正确
然后在第20层最高可能性的猜测变成华沙
这是正确的答案
并且在最后4层保持不变
布朗大学的研究人员发现第20个前馈层
通过添加了一个将国家向量映射到其对应首都的向量
从而将波兰转化为了华沙
将相同的向量添加到中国时候答案会得到北京
同一个模型中的前馈层会使用向量运算
将小写单词转换为大写单词
并将现在时的单词转换为过去时的等效词
到目前为止呢
我们已经看了
GPT-2单词预测的两个实际的示例
注意力头来帮助预测约翰给玛丽一杯饮料
而前馈层帮助预测华沙是波兰的首都
在第一个案例中
玛丽来自于用户提供的提示
但是在第二个案例中
华沙并没有出现在提示中
相反GPT-2必须记住华沙是波兰的首都
而这个信息呢是从训练数据中学到的
当布朗大学的研究人员禁用了
将波兰转化为华沙的前馈层时
模型就不再预测下一个词是华沙了
但是有趣的是
如果他们接着在提示的开头加上句子
波兰的首都是华沙
那么GPT2就能够再次回答这个问题
这可能是因为GPT2使用的注意力机制
从提示中提取到了华沙这个名字
这种分工会更广泛的表示为
注意力机制从提示的教导部分检索信息
而前馈层让语言模型能够记住
没有在提示中出现的信息
事实上你可以将前馈层
视为模型从训练数据中学到的信息的数据库
靠前的前馈层更可能编码与特定单词相关的简单事实
例如说
特朗普经常出现在唐纳德这个词之后
靠后的层则编码会更加复杂的关系
比如说加入这个向量来将国家转换为他的首都
以上呢我们就已经详细讲解了大语言模型的推理过程
接下来啊我们再讲一讲他的训练方式
许多早期的机器学习算法
都需要人工来标记训练示例
比如说训练数据呢可能是带有人工标签
狗或者猫的一些猫狗的照片
而正是需要标记数据的需求
使得人们想要创建足够大的数据集
来训练强大的模型这件事变得困难而且昂贵
大语言模型的一个关键的创新之处
就在于他们不需要显式的标记数据
相反呢他们通过尝试预测文本段落中的下一个单词
来学习几乎任何的书面材料
都可以用来训练这些模型
从维基百科的页面到新闻文章
再到计算机的代码
举个例子来说
单元模型可能会拿到一个输入
i like my coffee with cream and 某某
并且试图预测sugar糖作为下一个单词
一个新的初始化语言模型
在这方面表现的很糟糕
因为他的每个权重参数最初基本上都是从一个随机的数字开始的
但是随着模型看到更多的例子
比方说数千亿个单词
这些权重会逐渐的调整
从而做出更好的预测
直到像GPT-3最强大的版本一样
最后达到1,750亿个参数
下面呢我们用一个类比来说明这个过程是如何进行的
假设你要洗澡
希望水温刚刚好不太热也不太冷
你以前呢从来没有用过这个水龙头
所以你随意的去调整水龙头把手的这个方向啊
并触摸水的温度
如果太热或者太冷
你就会往相反的方向去转动把手
当接近适当的水温时候
你对把手所做的调整幅度呢就越小
现在让我们来对这个类比做几个改动
首先你想象一下有50,257个水龙头
每个水龙头对应着一个不同的单词
比如说the cat或者是bank
你的目标是只让与序列中下一个单词
相对应的水龙头里出水
其次水龙头后面有一大堆互连的管道
并且这些管道上呢还有一堆阀门
所以呢如果水从错误的水龙头里流出来了
你不能只是调整水龙头上的这个旋钮
你要派遣一只聪明的松鼠部队去追踪每条管道
并且沿途呢去调整他们找到的每个阀门
这样就会变得很复杂了
由于同一个管道经常会供应多个水龙头
所以需要仔细的思考如何确定要拧紧或者松开哪些阀门
以及到底拧多大程度
显然如果我们仅仅从字面上来理解
这个例子就会变得非常荒谬
建立一个拥有1,750亿个阀门的管道网络
既不现实也没有什么用
但是由于摩尔定律
计算机可以并且确实在以这种规模在运行
截止到目前
我们所讨论的大语言模型的所有部分
包括前馈层的神经元
以及在单词之间传递上下文信息的注意力头
都被实现为了一系列简单的数学函数
其中呢主要是矩阵乘法
它的行为由可调整的权重参数来确定
就像我故事中的松鼠来松紧阀门控制水流一样
训练算法是通过增加或者减少语言模型的权重参数
来控制信息在神经网络中的流动
训练过程分为两个步骤
首先进行前向传播forward pass
打开水源
并且检查水是否从正确的水龙头中流出
然后关闭水源
进行反向传播backwards pass
松鼠们就沿着每根管道飞快的奔跑
拧紧或者松开这个阀门
在数字化的神经网络中
松鼠的角色是由一个被称为反向传播的算法来扮演
这个算法会逆向的通过网络
使用微积分来评估需要改变每个权重参数的过程
对一个示例进行前向传播
然后再进行后向传播
来提高网络在这个示例上的性能
完成这个过程需要进行数百亿次的数学运算
而像GPT-3这种大模型的训练
需要重复这个过程数十亿次
因为对每个训练数据的每个词都要训练
OpenAI估计训练GPT-3
需要超过3,000亿万亿次的浮点计算
这需要几十个高端的GPU芯片运行数个月才能够完成
你可能会对训练过程能够如此出色的工作感到很惊讶
因为ChatGPT可以执行各种复杂的任务
包括撰写文章进行类比甚至编写计算机代码
那么这样一个简单的学习机制
是如何产生如此强大的模型呢
一个原因呢是规模
像GPT3这样的模型看到的示例数量是非常之多的
GPT3呢是在大约5,000亿个单词的语料库上进行训练的
相比之下
一个普通的人类孩子在10岁之前
遇到的单词数量大约是1亿个
在过去的五年中
OpenAI不断的增大他的大语言模型的规模
在一篇广为流传的2020年的论文中
OpenAI报告称
他们的语言模型的准确性与语言规模数据集规模
以及用于训练的计算量呈幂率关系
一些趋势呢甚至跨越7个数量级以上
模型规模越大
在涉及语言的任务上表现的越好
但是前提是他们需要以类似的倍数来增加训练数据量
而且要在更多的数据上训练更大的模型
还需要更多的算力
2018年OpenAI发布了第一个大模型GPT-1
它使用了768维的词向量共有12层
总共有1.17亿个参数
几个月后
OpenAI发布了GPT-2
它最大的版本拥有1,600维的词向量
48层总共有15亿个参数
2020年OpenAI发布了GPT-3
它具有12,288维的词向量
96层总共有1,751个参数
今年OpenAI发布了GPT-4
虽然尚没有公布任何的架构细节
但是业内普遍认为GPT-4比GPT-3要大得多
每个模型不仅学到了比他较小的前身模型更多的事实
而且在需要某种形式的抽象推理任务上
表现出了更好的性能
比如说我们设想这样一个故事
一个装满了爆米花的袋子
袋子里没有巧克力
但是袋子上的标签写着是巧克力
而不是爆米花
一个小孩山姆发现了这个袋子
他以前从来没有见过这个袋子
他也看不见袋子里面的东西
他读到了这个袋子上的标签
你可能会猜
山姆相信袋子里面装着巧克力
并且会惊讶的发现里面其实是爆米花
心理学家将这种推理他人思维状态的能力研究
称之为心智理论theory of mind
大多数人从上小学开始就具备了这种能力
虽然专家们对于任何非人类的动物
比如说黑猩猩是否适用于这种心智理论存在分歧
但是基本的共识是他对人类社会的认知至关重要
今年的早些时间
斯坦福大学心理学家米哈尔科兴斯基发表了一项研究
研究了大圆模型的能力是否能够解决心智理论的任务
他给各种语言模型阅读了类似刚刚我们讲的那个故事
然后要求他们完成一个句子
比如说他相信袋子里面装满了什么
正确答案呢应该是巧克力
但是一个不成熟的语言模型
可能会说成是爆米花或者其他东西
GPT-1和GPT-2在这个测试中失败了
但在2020年发布的GPT-3的第一个版本中
正确率达到了接近于40%
科辛斯基将模型的性能水平与3岁的儿童相比较
去年11月份发布的最新版的GPT-3
将上述问题的正确率提高到了大约90%
与7岁的儿童相当
而GPT-4对心智理论问题的回答正确率呢约为95%
科辛斯基写道
鉴于这些模型中既没有迹象表明
心智化能力被有意的设计进去
也没有研究证明科学家知道如何实现它
这个能力很可能是自发而且自主的出现的
这就是模型的语言能力不断增强的一个副产品
不过呢值得注意的是
研究人员并不全都认可这些结果证明了心智理论
比如说有的人发现
对错误信念任务的微小更改
会导致GPT-3的性能大大的下降
而GPT-3在测量心智理论的其他任务中的表现更为不稳定
正如肖恩写Hans的那样
成功的表现可能是归于任务中的混淆因素
这是一种聪明汉斯的效应
英文呢是clever Hans
指的是一匹名为汉斯的马
看似呢能够完成一些简单的智力任务
但是实际上只是依赖于人们给出的无意识的线索
只不过这个效应现在是出现了大语言模型上
而不是马身上
尽管如此GPT-3在几个衡量心智理论的任务上
接近于人类的表现
这在几年前呢是无法想象的
并且这与更大的模型
通常在需要高级推理的任务中表现的更好的观点是相一致的
这只是语言模型表现出的
自发发展出高级推理能力的众多的例子之一
今年4月呢
微软的研究人员发表了一篇论文
也表示GPT-4展示了通用人工智能的初步诱人的迹象
即以一种复杂类人的方式去思考的能力
比方说呢
一名研究人员要求GPT-4
使用一种名为TiKZ的晦涩的图形编程语言
画一只独角兽
GPT-4回应了几行代码
然后研究人员将这些代码输入
TiKZ软件生成的图像呢虽然粗糙
但是清晰的显示出
GPT-4对独角兽的外观有一定的理解
研究人员认为
GPT-4可能以某种方式从训练数据中
记住了绘制独角兽的代码
所以他们给他提出了一个后续的挑战
他们修改了独角兽的代码移除了头部的角
并且呢移动了一其他的一些身体部位
然后他们让GPT-4把独角兽头上的角放回去
而GPT-4的回应呢
正是将头上的角放在了正确的位置上
尽管作者的测试版本和训练数据
完全是基于文本的
没有包含任何的图像
但是GBT-4似乎仍然能够完成这个任务
不过呢通过大量的书面文本训练之后
GPT-4显然学会了推理关于独角兽身体形状的知识
目前呢我们对于大语言模型如何完成这样的壮举
没有真正的了解
有些人认为呢像这样的例子表明
模型开始真正理解训练集中词的含义
而其他人呢则坚持认为
语言模型呢只是一种随机鹦鹉
仅仅是重复越来越复杂的单词序列
而并非真正理解他们
那关于什么是随机鹦鹉
我们找时间也会专门去介绍一下
这种辩论指向了一种深刻的哲学争论
可能无法解决
尽管如此
我们认为关注GPT-3这些模型的经验表现
也是很重要的
如果一个语言模型
能够在特定类型的问题中始终得到正确的答案
并且呢研究人员有信心排除掉混淆的因素
比如说可以确保模型在训练期间没有接触过这些问题
那么无论他们对语言的理解方式
是否跟人类完全相同
这都是一个有趣而且重要的结果
训练下一个token预测如此有效的另外一个可能的原因
就是语言本身是可以预测的
语言的规律性通常会跟物质世界的规律性相关联
因此当语言模型学习单词之间的关系时候
通常也在隐含的学习跟这个世界存在的关系
此外呢预测可能是生物智能以及人工智能的一个基础
根据Andy Clark等哲学家的观点
人脑呢可以被认为是一个预测机器
它的主要任务呢
是对我们的环境进行预测
然后利用这些预测来成功的驾驭环境
预测对于生物智能和人工智能都至关重要
直观的说
好的预测离不开良好的表示
比如说准确的地图比错误的地图
更有可能帮助人们去更好的导航
世界是广阔而复杂的
进行预测有助于生物高效定位和适应这种复杂性
在构建语言模型方面
传统上的一个重大的挑战
就是如何找出最有用的表示不同单词的方式
特别是因为许多单词的含义很大程度上取决于上下文
下一个词的预测方法
使得研究人员能够将其转换成一个经验性的问题
以此来避开这个棘手的理论难题
事实证明
如果我们提供足够的数据和计算能力
大语言模型能够通过找出最佳的下一个词的预测
来学习人类语言的运作方式
它的不足之处在于
最终得到的系统内部的运作方式
人类目前还并不能完全的理解
好了以上就是对大语言模型整个工作原理的一个解释
不知道大家理解了多少
整个内容呢大概13,000多字
光是录制视频就录了一个多小时
所以还希望大家多多的点赞评论和转发
也希望这个视频能够帮助到大家
对现在的大语言模型有一个基础的理解
感谢大家的观看
我们下期再见
5.0 / 5 (0 votes)

Simple Introduction to Large Language Models (LLMs)

Why & When You Should Use Claude 3 Over ChatGPT

【機器學習2021】Transformer (上)
Can LLMs reason? | Yann LeCun and Lex Fridman

37% Better Output with 15 Lines of Code - Llama 3 8B (Ollama) & 70B (Groq)

New OpenAI Model 'Imminent' and AI Stakes Get Raised (plus Med Gemini, GPT 2 Chatbot and Scale AI)